 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Share or not to Share: Predicting Sets of Sources for Model Transfer Learning
Paper and Code
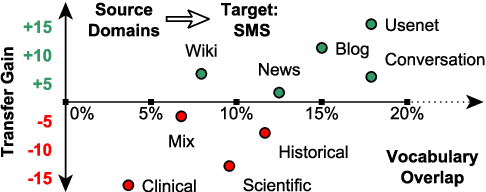
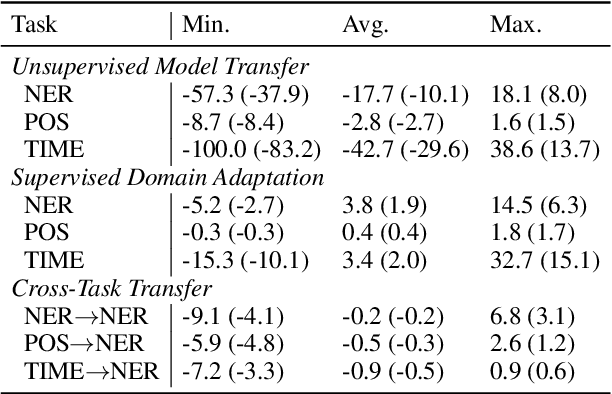
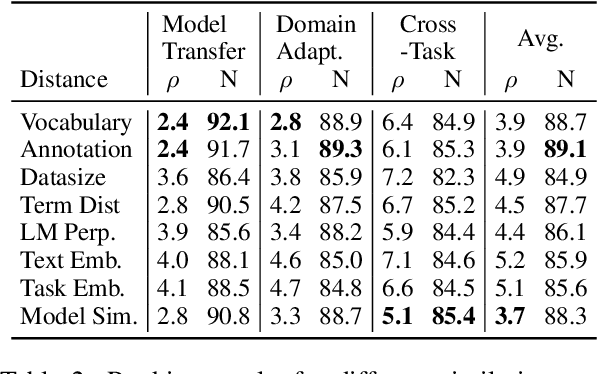
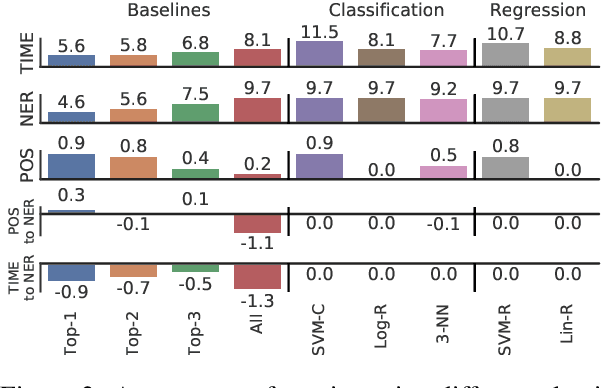
In low-resource settings, model transfer can help to overcome a lack of labeled data for many tasks and domains. However, predicting useful transfer sources is a challenging problem, as even the most similar sources might lead to unexpected negative transfer results. Thus, ranking methods based on task and text similarity may not be sufficient to identify promising sources. To tackle this problem, we propose a method to automatically determine which and how many sources should be exploited. For this, we study the effects of model transfer on sequence labeling across various domains and tasks and show that our methods based on model similarity and support vector machines are able to predict promising sources, resulting in performance increases of up to 24 F1 points.