 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Datasets with Pretrained Language Models
Paper and Code
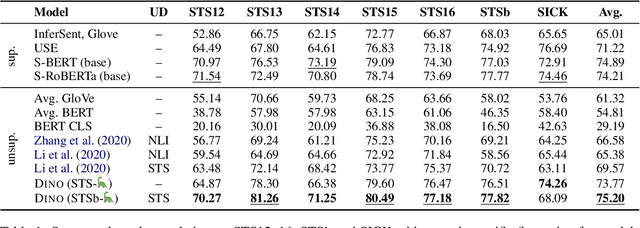



To obtain high-quality sentence embeddings from pretrained language models (PLMs), they must either be augmented with additional pretraining objectives or finetuned on a large set of labeled text pairs. While the latter approach typically outperforms the former, it requires great human effort to generate suitable datasets of sufficient size. In this paper, we show how large PLMs can be leveraged to obtain high-quality embeddings without requiring any labeled data, finetuning or modifications to the pretraining objective: We utilize the generative abilities of PLMs to generate entire datasets of labeled text pairs from scratch, which can then be used for regular finetuning of much smaller models. Our fully unsupervised approach outperforms strong baselines on several English semantic textual similarity datasets.