 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Bias in Automatic Speech Recognition
Paper and Code
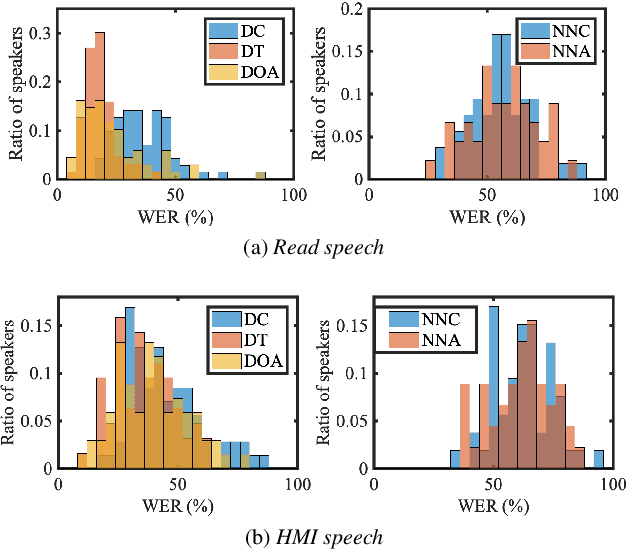
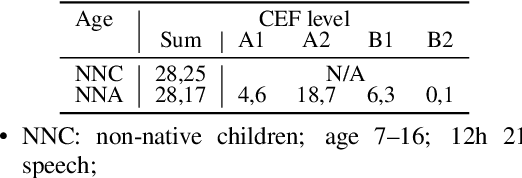
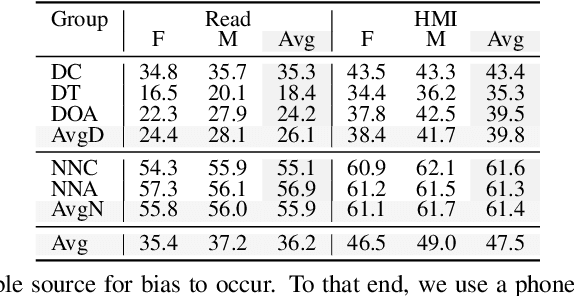
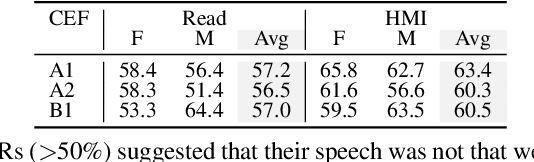
Automatic speech recognition (ASR) systems promise to deliver objective interpretation of human speech. Practice and recent evidence suggests that the state-of-the-art (SotA) ASRs struggle with the large variation in speech due to e.g., gender, age, speech impairment, race, and accents. Many factors can cause the bias of an ASR system. Our overarching goal is to uncover bias in ASR systems to work towards proactive bias mitigation in ASR. This paper is a first step towards this goal and systematically quantifies the bias of a Dutch SotA ASR system against gender, age, regional accents and non-native accents. Word error rates are compared, and an in-depth phoneme-level error analysis is conducted to understand where bias is occurring. We primarily focus on bias due to articulation differences in the dataset. Based on our findings, we suggest bias mitigation strategies for ASR development.