 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadically Old Way of Computing Spectra: Applications in End-to-End ASR
Paper and Code
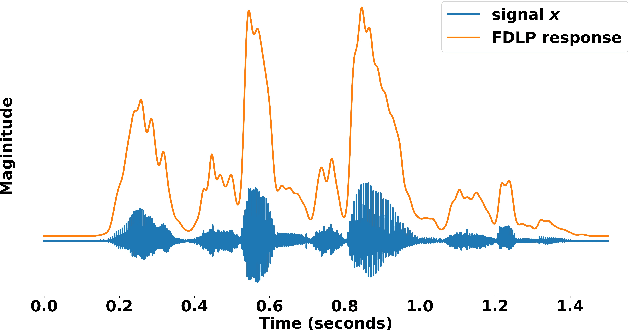

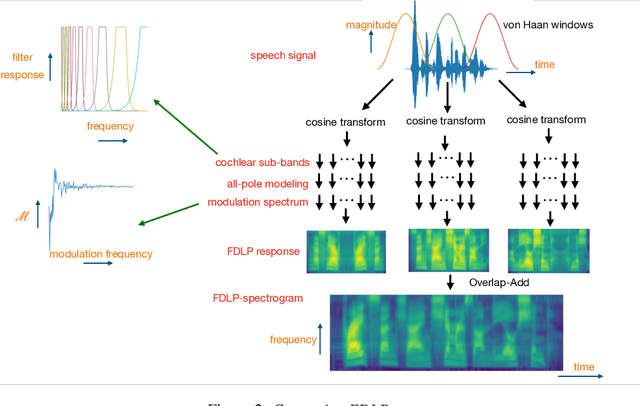

We propose a technique to compute spectrograms using Frequency Domain Linear Prediction (FDLP) that uses all-pole models to fit the squared Hilbert envelope of speech in different frequency sub-bands. The spectrogram of a complete speech utterance is computed by overlap-add of contiguous all-pole model responses. A long context window of 1.5 seconds allows us to capture the low frequency temporal modulations of speech in the spectrogram. For an end-to-end automatic speech recognition task, the FDLP spectrogram performs on par with the standard mel spectrogram features for clean read speech training and test data. For more realistic speech data with train-test domain mismatches or reverberations, FDLP spectrogram shows up to 25% and 22% relative WER improvements over mel spectrogram respectively.