 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Reward Information from Multiple Sources
Paper and Code
Mar 22, 2021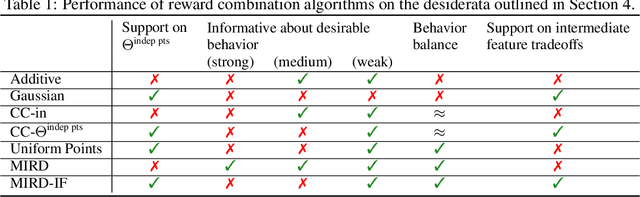
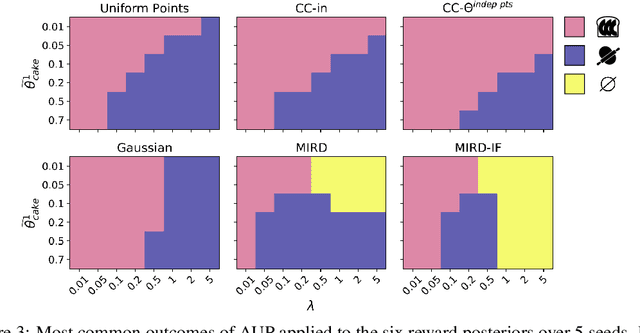
Given two sources of evidence about a latent variable, one can combine the information from both by multiplying the likelihoods of each piece of evidence. However, when one or both of the observation models are misspecified, the distributions will conflict. We study this problem in the setting with two conflicting reward functions learned from different sources. In such a setting, we would like to retreat to a broader distribution over reward functions, in order to mitigate the effects of misspecification. We assume that an agent will maximize expected reward given this distribution over reward functions, and identify four desiderata for this setting. We propose a novel algorithm, Multitask Inverse Reward Design (MIRD), and compare it to a range of simple baselines. While all methods must trade off between conservatism and informativeness, through a combination of theory and empirical results on a toy environment, we find that MIRD and its variant MIRD-IF strike a good balance between the two.