 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseGAN: Sparse Generative Adversarial Network for Text Generation
Paper and Code
Mar 22, 2021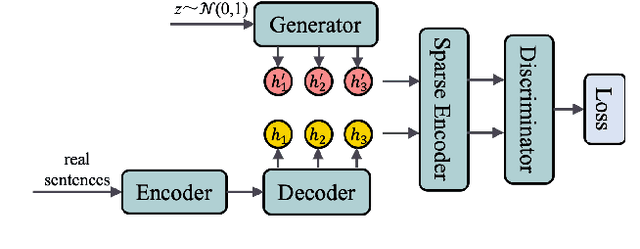
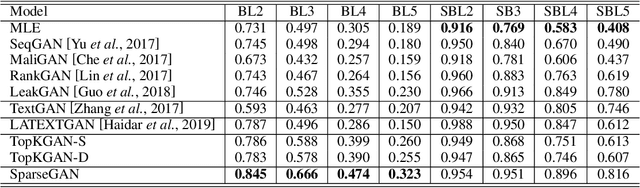

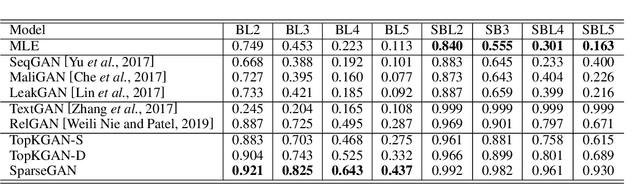
It is still a challenging task to learn a neural text generation model under the framework of generative adversarial networks (GANs) since the entire training process is not differentiable. The existing training strategies either suffer from unreliable gradient estimations or imprecise sentence representations. Inspired by the principle of sparse coding, we propose a SparseGAN that generates semantic-interpretable, but sparse sentence representations as inputs to the discriminator. The key idea is that we treat an embedding matrix as an over-complete dictionary, and use a linear combination of very few selected word embeddings to approximate the output feature representation of the generator at each time step. With such semantic-rich representations, we not only reduce unnecessary noises for efficient adversarial training, but also make the entire training process fully differentiable. Experiments on multiple text generation datasets yield performance improvements, especially in sequence-level metrics, such as BLEU.