 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANITA: An Optimal Loopless Accelerated Variance-Reduced Gradient Method
Paper and Code
Mar 21, 2021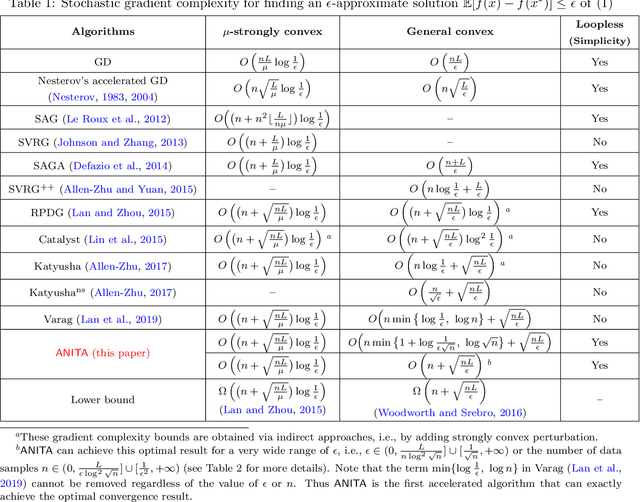
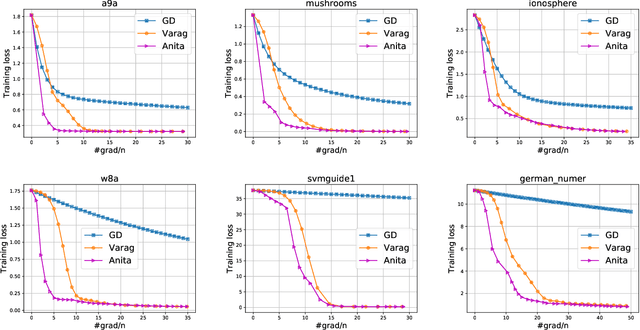

We propose a novel accelerated variance-reduced gradient method called ANITA for finite-sum optimization. In this paper, we consider both general convex and strongly convex settings. In the general convex setting, ANITA achieves the convergence result $O\big(n\min\big\{1+\log\frac{1}{\epsilon\sqrt{n}}, \log\sqrt{n}\big\} + \sqrt{\frac{nL}{\epsilon}} \big)$, which improves the previous best result $O\big(n\min\{\log\frac{1}{\epsilon}, \log n\}+\sqrt{\frac{nL}{\epsilon}}\big)$ given by Varag (Lan et al., 2019). In particular, for a very wide range of $\epsilon$, i.e., $\epsilon \in (0,\frac{L}{n\log^2\sqrt{n}}]\cup [\frac{1}{\sqrt{n}},+\infty)$, where $\epsilon$ is the error tolerance $f(x_T)-f^*\leq \epsilon$ and $n$ is the number of data samples, ANITA can achieve the optimal convergence result $O\big(n+\sqrt{\frac{nL}{\epsilon}}\big)$ matching the lower bound $\Omega\big(n+\sqrt{\frac{nL}{\epsilon}}\big)$ provided by Woodworth and Srebro (2016). To the best of our knowledge, ANITA is the \emph{first} accelerated algorithm which can \emph{exactly} achieve this optimal result $O\big(n+\sqrt{\frac{nL}{\epsilon}}\big)$ for general convex finite-sum problems. In the strongly convex setting, we also show that ANITA can achieve the optimal convergence result $O\Big(\big(n+\sqrt{\frac{nL}{\mu}}\big)\log\frac{1}{\epsilon}\Big)$ matching the lower bound $\Omega\Big(\big(n+\sqrt{\frac{nL}{\mu}}\big)\log\frac{1}{\epsilon}\Big)$ provided by Lan and Zhou (2015). Moreover, ANITA enjoys a simpler loopless algorithmic structure unlike previous accelerated algorithms such as Katyusha (Allen-Zhu, 2017) and Varag (Lan et al., 2019) where they use an inconvenient double-loop structure. Finally, the experimental results also show that ANITA converges faster than previous state-of-the-art Varag (Lan et al., 2019), validating our theoretical results and confirming the practical superiority of ANITA.