 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Context-Free and Contextualized Representations for Arabic Sarcasm Detection and Sentiment Identification
Paper and Code
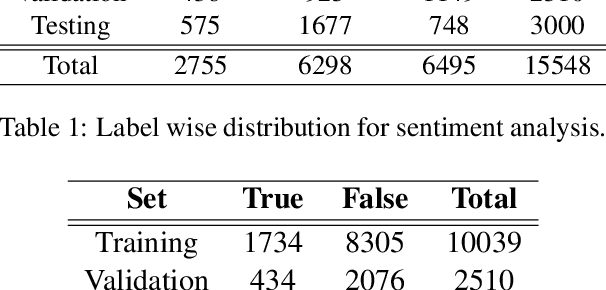
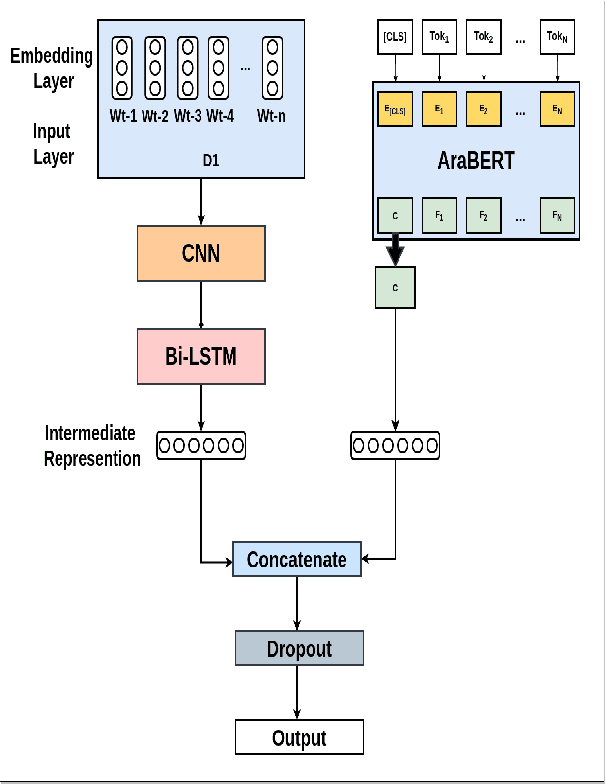
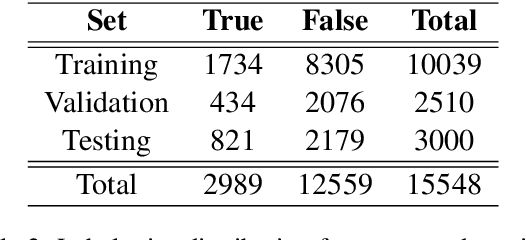
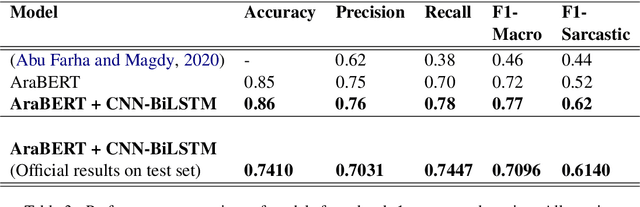
Since their inception, transformer-based language models have led to impressive performance gains across multiple natural language processing tasks. For Arabic, the current state-of-the-art results on most datasets are achieved by the AraBERT language model. Notwithstanding these recent advancements, sarcasm and sentiment detection persist to be challenging tasks in Arabic, given the language's rich morphology, linguistic disparity and dialectal variations. This paper proffers team SPPU-AASM's submission for the WANLP ArSarcasm shared-task 2021, which centers around the sarcasm and sentiment polarity detection of Arabic tweets. The study proposes a hybrid model, combining sentence representations from AraBERT with static word vectors trained on Arabic social media corpora. The proposed system achieves a F1-sarcastic score of 0.62 and a F-PN score of 0.715 for the sarcasm and sentiment detection tasks, respectively. Simulation results show that the proposed system outperforms multiple existing approaches for both the tasks, suggesting that the amalgamation of context-free and context-dependent text representations can help capture complementary facets of word meaning in Arabic. The system ranked second and tenth in the respective sub-tasks of sarcasm detection and sentiment identification.