 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShift Equivariance for Pixel-based Self-supervised SAR-optical Feature Fusion
Paper and Code
Mar 13, 2021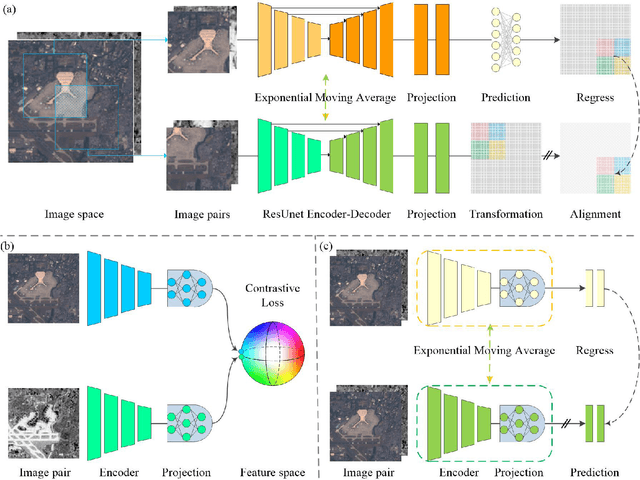
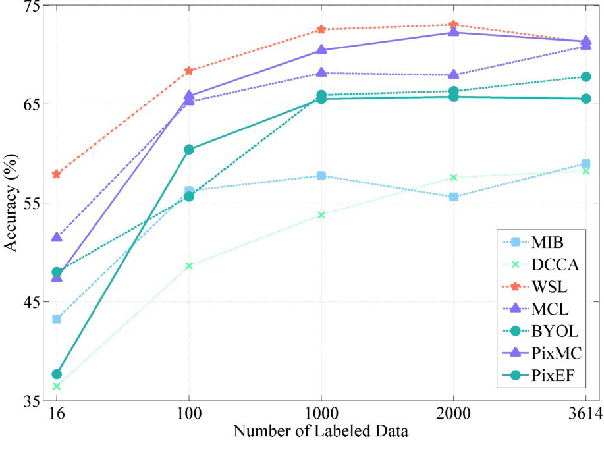
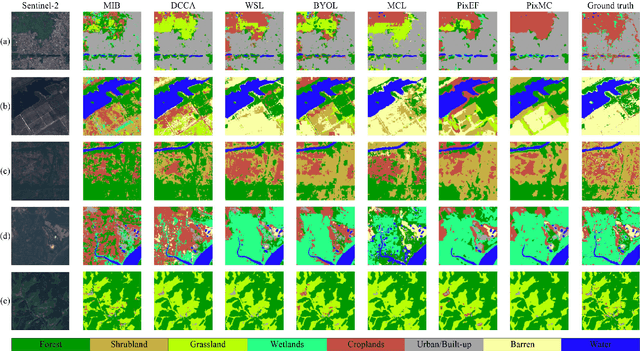
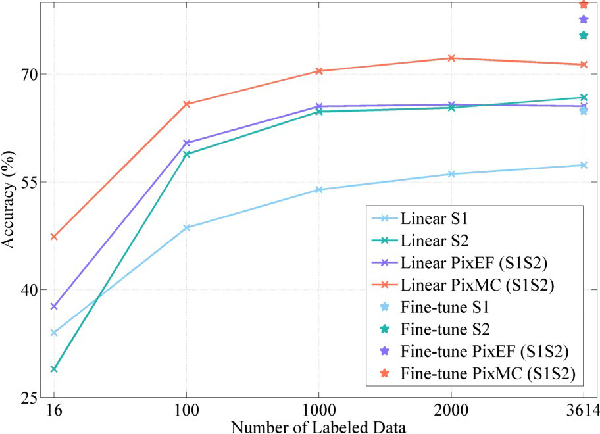
The effective combination of the complementary information provided by the huge amount of unlabeled multi-sensor data (e.g., Synthetic Aperture Radar (SAR), optical images) is a critical topic in remote sensing. Recently, contrastive learning methods have reached remarkable success in obtaining meaningful feature representations from multi-view data. However, these methods only focus on the image-level features, which may not satisfy the requirement for dense prediction tasks such as the land-cover mapping. In this work, we propose a new self-supervised approach to SAR-optical data fusion that can learn disentangled pixel-wise feature representations directly by taking advantage of both multi-view contrastive loss and the bootstrap your own latent (BYOL) methods. Two key contributions of the proposed approach are a multi-view contrastive loss to encode the multimodal images and a shift operation to reconstruct learned representations for each pixel by building the local consistency between different augmented views. In the experimental period, we first verified the effectiveness of multi-view contrastive loss and BYOL in self-supervised learning on SAR-optical fusion using an image-level classification task. Then we validated the proposed approach on a land-cover mapping task by training it with unlabeled SAR-optical image pairs. There we used labeled data pairs to evaluate the discriminative capability of learned features in downstream tasks. Results show that the proposed approach extracts features that result in higher accuracy and that reduces the dimension of representations with respect to the image-level contrastive learning method.