 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore data or more parameters? Investigating the effect of data structure on generalization
Paper and Code
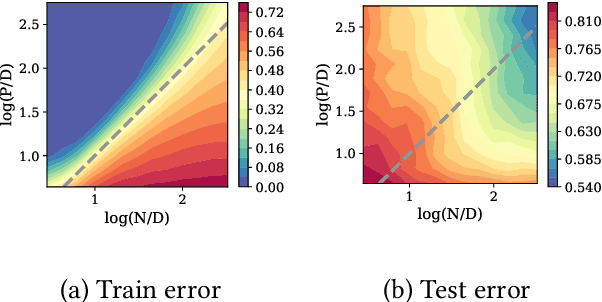
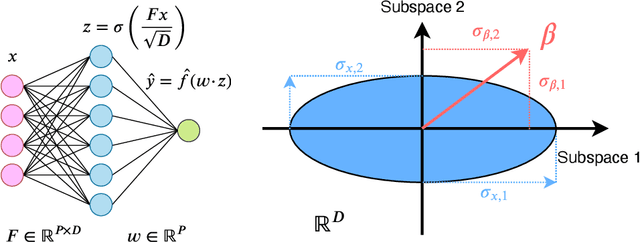
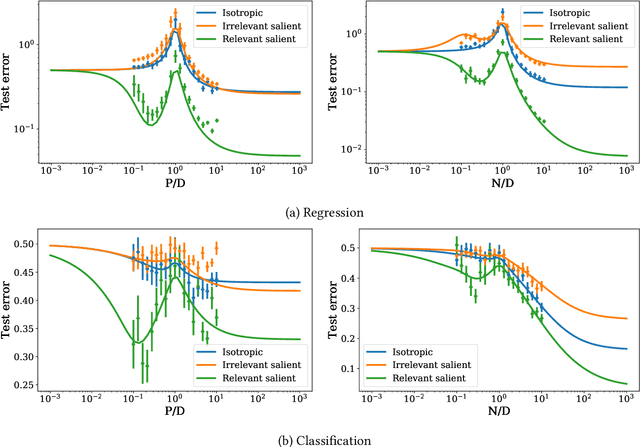
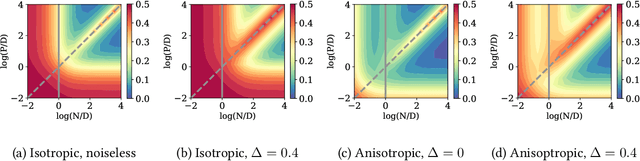
One of the central features of deep learning is the generalization abilities of neural networks, which seem to improve relentlessly with over-parametrization. In this work, we investigate how properties of data impact the test error as a function of the number of training examples and number of training parameters; in other words, how the structure of data shapes the "generalization phase space". We first focus on the random features model trained in the teacher-student scenario. The synthetic input data is composed of independent blocks, which allow us to tune the saliency of low-dimensional structures and their relevance with respect to the target function. Using methods from statistical physics, we obtain an analytical expression for the train and test errors for both regression and classification tasks in the high-dimensional limit. The derivation allows us to show that noise in the labels and strong anisotropy of the input data play similar roles on the test error. Both promote an asymmetry of the phase space where increasing the number of training examples improves generalization further than increasing the number of training parameters. Our analytical insights are confirmed by numerical experiments involving fully-connected networks trained on MNIST and CIFAR10.