 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Implicit Attribute Localization for Generalized Zero-Shot Learning
Paper and Code
Mar 08, 2021
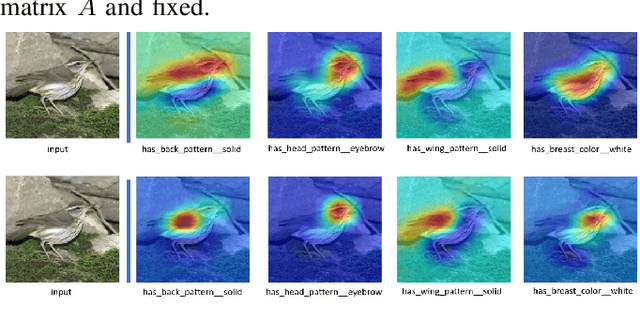

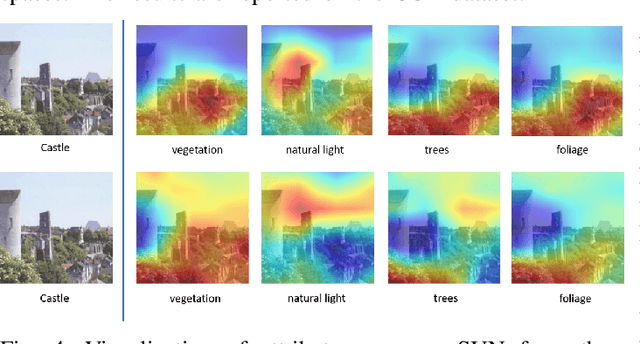
Zero-shot learning (ZSL) aims to discriminate images from unseen classes by exploiting relations to seen classes via their attribute-based descriptions. Since attributes are often related to specific parts of objects, many recent works focus on discovering discriminative regions. However, these methods usually require additional complex part detection modules or attention mechanisms. In this paper, 1) we show that common ZSL backbones (without explicit attention nor part detection) can implicitly localize attributes, yet this property is not exploited. 2) Exploiting it, we then propose SELAR, a simple method that further encourages attribute localization, surprisingly achieving very competitive generalized ZSL (GZSL) performance when compared with more complex state-of-the-art methods. Our findings provide useful insight for designing future GZSL methods, and SELAR provides an easy to implement yet strong baseline.