 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing the Value of Labeled and Unlabeled Data in Method-of-Moments Latent Variable Estimation
Paper and Code
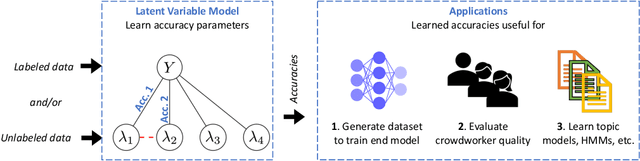
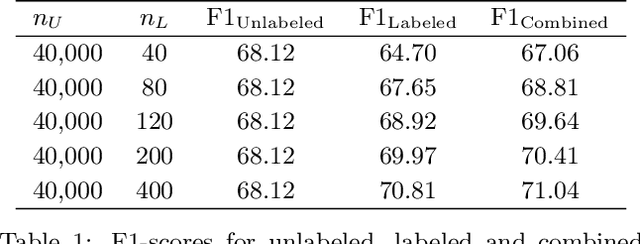
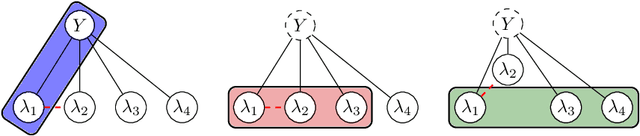

Labeling data for modern machine learning is expensive and time-consuming. Latent variable models can be used to infer labels from weaker, easier-to-acquire sources operating on unlabeled data. Such models can also be trained using labeled data, presenting a key question: should a user invest in few labeled or many unlabeled points? We answer this via a framework centered on model misspecification in method-of-moments latent variable estimation. Our core result is a bias-variance decomposition of the generalization error, which shows that the unlabeled-only approach incurs additional bias under misspecification. We then introduce a correction that provably removes this bias in certain cases. We apply our decomposition framework to three scenarios -- well-specified, misspecified, and corrected models -- to 1) choose between labeled and unlabeled data and 2) learn from their combination. We observe theoretically and with synthetic experiments that for well-specified models, labeled points are worth a constant factor more than unlabeled points. With misspecification, however, their relative value is higher due to the additional bias but can be reduced with correction. We also apply our approach to study real-world weak supervision techniques for dataset construction.