 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavTuner: Learning a Scene-Sensitive Family of Navigation Policies
Paper and Code
Mar 02, 2021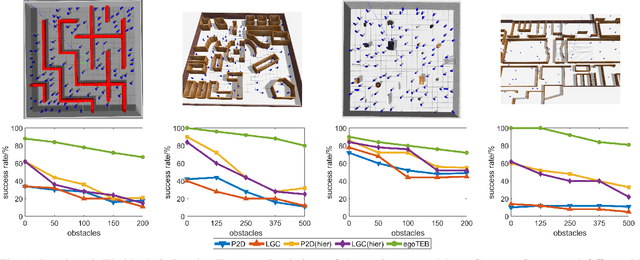
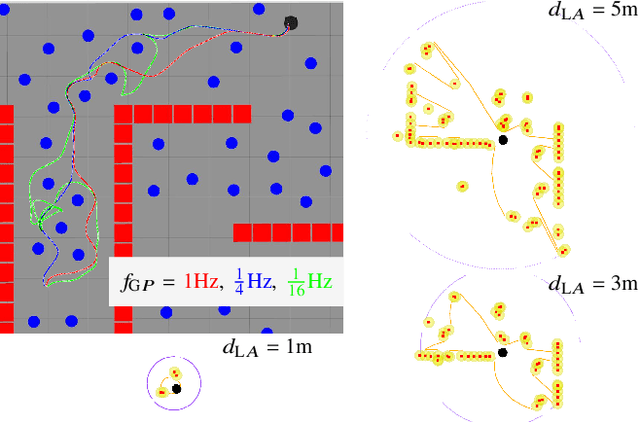

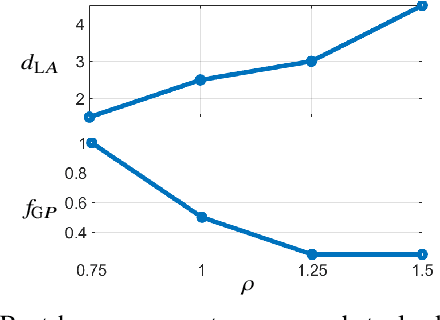
The advent of deep learning has inspired research into end-to-end learning for a variety of problem domains in robotics. For navigation, the resulting methods may not have the generalization properties desired let alone match the performance of traditional methods. Instead of learning a navigation policy, we explore learning an adaptive policy in the parameter space of an existing navigation module. Having adaptive parameters provides the navigation module with a family of policies that can be dynamically reconfigured based on the local scene structure, and addresses the common assertion in machine learning that engineered solutions are inflexible. Of the methods tested, reinforcement learning (RL) is shown to provide a significant performance boost to a modern navigation method through reduced sensitivity of its success rate to environmental clutter. The outcomes indicate that RL as a meta-policy learner, or dynamic parameter tuner, effectively robustifies algorithms sensitive to external, measurable nuisance factors.