 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized and Transferable Patient Language Representation for Phenotyping with Limited Data
Paper and Code
Feb 24, 2021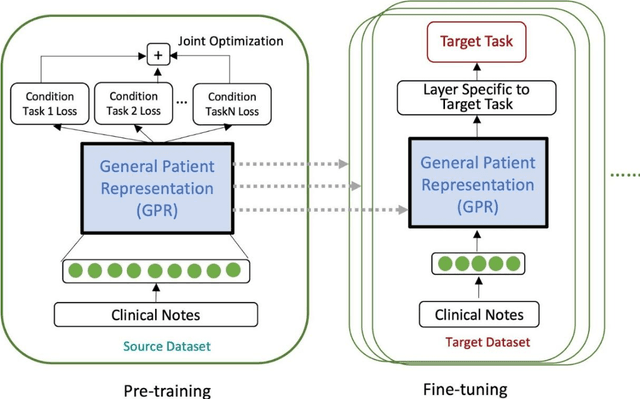
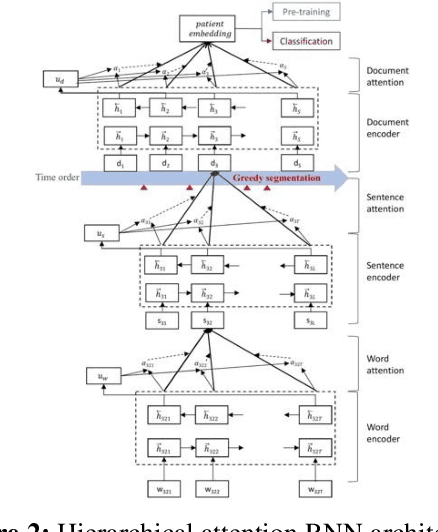
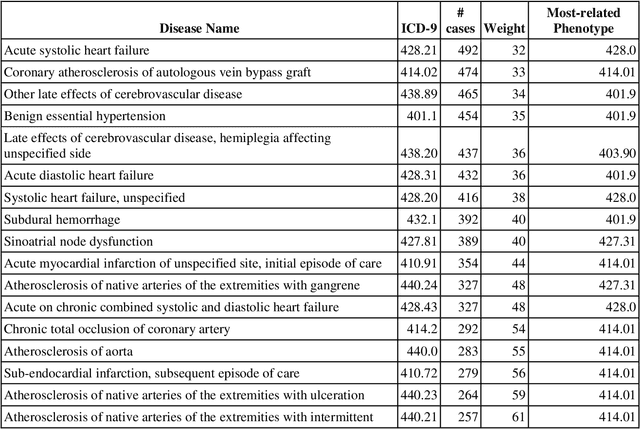
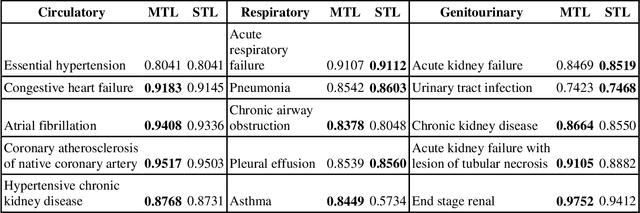
The paradigm of representation learning through transfer learning has the potential to greatly enhance clinical natural language processing. In this work, we propose a multi-task pre-training and fine-tuning approach for learning generalized and transferable patient representations from medical language. The model is first pre-trained with different but related high-prevalence phenotypes and further fine-tuned on downstream target tasks. Our main contribution focuses on the impact this technique can have on low-prevalence phenotypes, a challenging task due to the dearth of data. We validate the representation from pre-training, and fine-tune the multi-task pre-trained models on low-prevalence phenotypes including 38 circulatory diseases, 23 respiratory diseases, and 17 genitourinary diseases. We find multi-task pre-training increases learning efficiency and achieves consistently high performance across the majority of phenotypes. Most important, the multi-task pre-training is almost always either the best-performing model or performs tolerably close to the best-performing model, a property we refer to as robust. All these results lead us to conclude that this multi-task transfer learning architecture is a robust approach for developing generalized and transferable patient language representations for numerous phenotypes.