 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy Truncated SGD: Optimization and Generalization
Paper and Code
Feb 26, 2021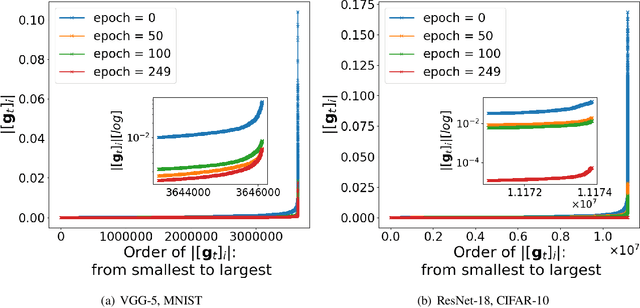
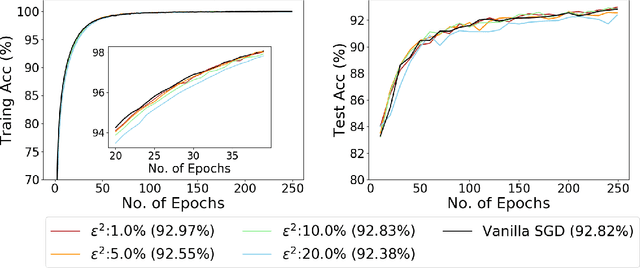
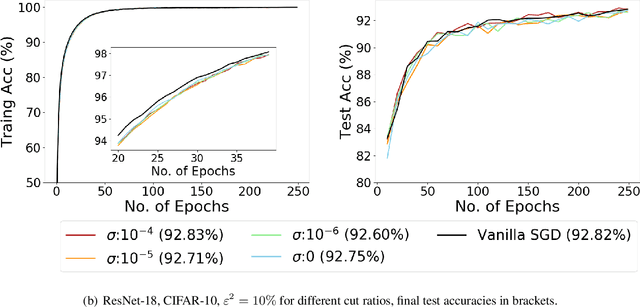
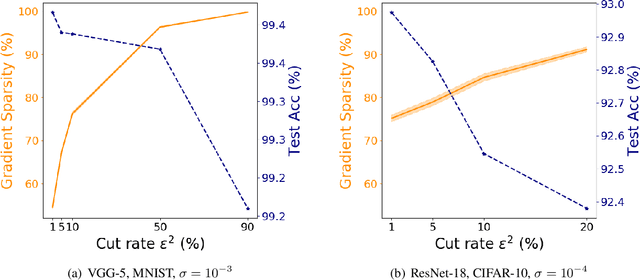
Recent empirical work on SGD applied to over-parameterized deep learning has shown that most gradient components over epochs are quite small. Inspired by such observations, we rigorously study properties of noisy truncated SGD (NT-SGD), a noisy gradient descent algorithm that truncates (hard thresholds) the majority of small gradient components to zeros and then adds Gaussian noise to all components. Considering non-convex smooth problems, we first establish the rate of convergence of NT-SGD in terms of empirical gradient norms, and show the rate to be of the same order as the vanilla SGD. Further, we prove that NT-SGD can provably escape from saddle points and requires less noise compared to previous related work. We also establish a generalization bound for NT-SGD using uniform stability based on discretized generalized Langevin dynamics. Our experiments on MNIST (VGG-5) and CIFAR-10 (ResNet-18) demonstrate that NT-SGD matches the speed and accuracy of vanilla SGD, and can successfully escape sharp minima while having better theoretical properties.