 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with invariances in random features and kernel models
Paper and Code
Feb 25, 2021
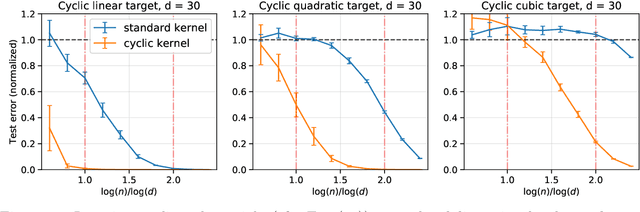
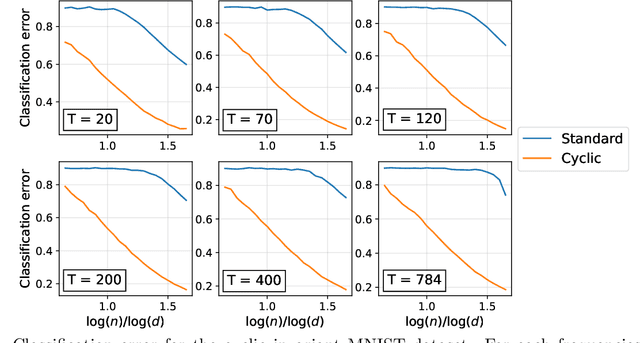
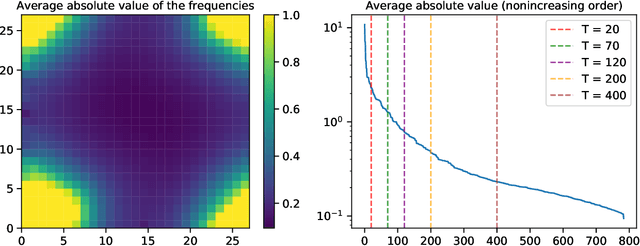
A number of machine learning tasks entail a high degree of invariance: the data distribution does not change if we act on the data with a certain group of transformations. For instance, labels of images are invariant under translations of the images. Certain neural network architectures -- for instance, convolutional networks -- are believed to owe their success to the fact that they exploit such invariance properties. With the objective of quantifying the gain achieved by invariant architectures, we introduce two classes of models: invariant random features and invariant kernel methods. The latter includes, as a special case, the neural tangent kernel for convolutional networks with global average pooling. We consider uniform covariates distributions on the sphere and hypercube and a general invariant target function. We characterize the test error of invariant methods in a high-dimensional regime in which the sample size and number of hidden units scale as polynomials in the dimension, for a class of groups that we call `degeneracy $\alpha$', with $\alpha \leq 1$. We show that exploiting invariance in the architecture saves a $d^\alpha$ factor ($d$ stands for the dimension) in sample size and number of hidden units to achieve the same test error as for unstructured architectures. Finally, we show that output symmetrization of an unstructured kernel estimator does not give a significant statistical improvement; on the other hand, data augmentation with an unstructured kernel estimator is equivalent to an invariant kernel estimator and enjoys the same improvement in statistical efficiency.