 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Safe Continuing Task Reinforcement Learning
Paper and Code
Feb 24, 2021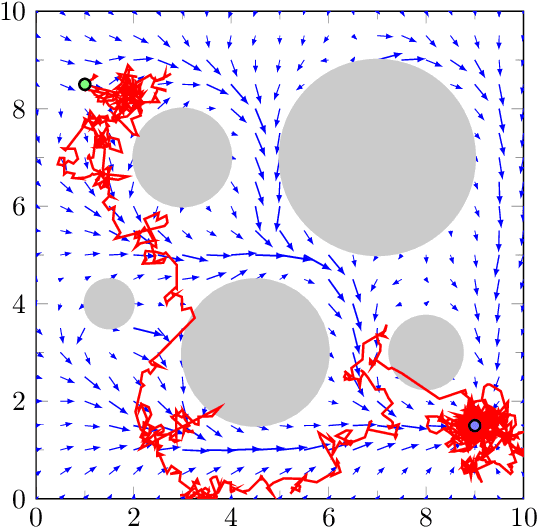
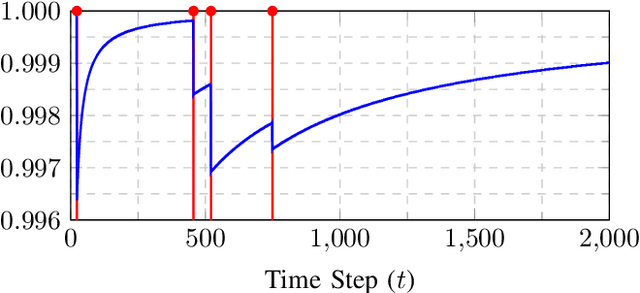
Safety is a critical feature of controller design for physical systems. When designing control policies, several approaches to guarantee this aspect of autonomy have been proposed, such as robust controllers or control barrier functions. However, these solutions strongly rely on the model of the system being available to the designer. As a parallel development, reinforcement learning provides model-agnostic control solutions but in general, it lacks the theoretical guarantees required for safety. Recent advances show that under mild conditions, control policies can be learned via reinforcement learning, which can be guaranteed to be safe by imposing these requirements as constraints of an optimization problem. However, to transfer from learning safety to learning safely, there are two hurdles that need to be overcome: (i) it has to be possible to learn the policy without having to re-initialize the system; and (ii) the rollouts of the system need to be in themselves safe. In this paper, we tackle the first issue, proposing an algorithm capable of operating in the continuing task setting without the need of restarts. We evaluate our approach in a numerical example, which shows the capabilities of the proposed approach in learning safe policies via safe exploration.