 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Call the Plumber: Orchestrating Dynamic Information Extraction Pipelines
Paper and Code
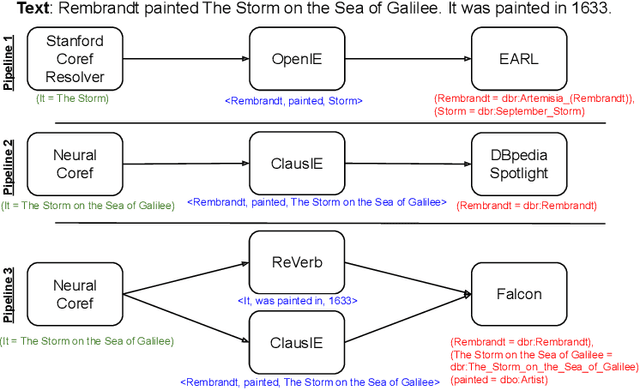
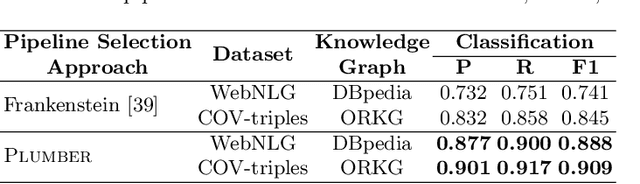
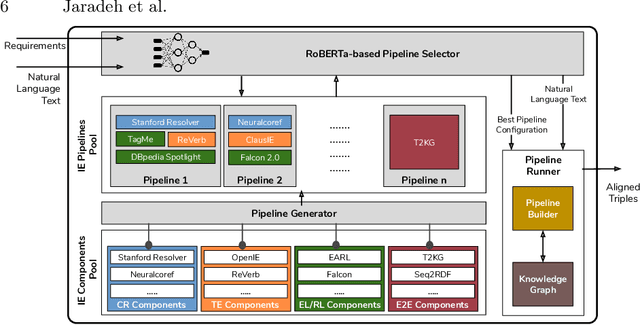
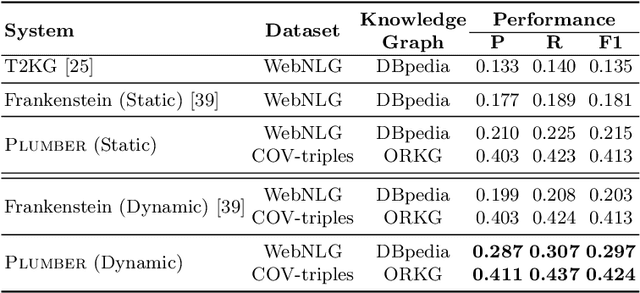
In the last decade, a large number of Knowledge Graph (KG) information extraction approaches were proposed. Albeit effective, these efforts are disjoint, and their collective strengths and weaknesses in effective KG information extraction (IE) have not been studied in the literature. We propose Plumber, the first framework that brings together the research community's disjoint IE efforts. The Plumber architecture comprises 33 reusable components for various KG information extraction subtasks, such as coreference resolution, entity linking, and relation extraction. Using these components,Plumber dynamically generates suitable information extraction pipelines and offers overall 264 distinct pipelines.We study the optimization problem of choosing suitable pipelines based on input sentences. To do so, we train a transformer-based classification model that extracts contextual embeddings from the input and finds an appropriate pipeline. We study the efficacy of Plumber for extracting the KG triples using standard datasets over two KGs: DBpedia, and Open Research Knowledge Graph (ORKG). Our results demonstrate the effectiveness of Plumber in dynamically generating KG information extraction pipelines,outperforming all baselines agnostics of the underlying KG. Furthermore,we provide an analysis of collective failure cases, study the similarities and synergies among integrated components, and discuss their limitations.