 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcho State Speech Recognition
Paper and Code
Feb 18, 2021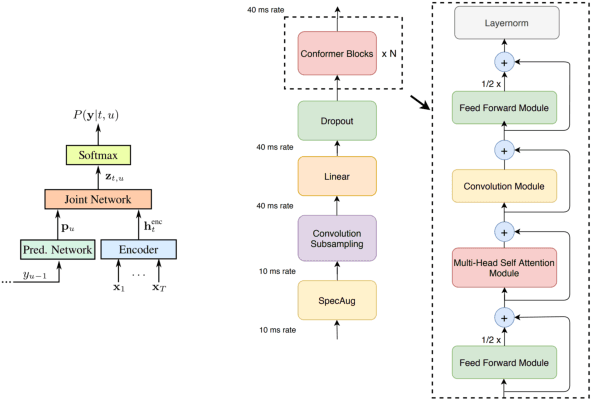
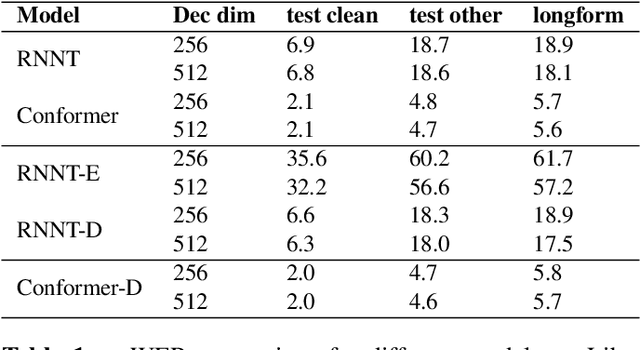

We propose automatic speech recognition (ASR) models inspired by echo state network (ESN), in which a subset of recurrent neural networks (RNN) layers in the models are randomly initialized and untrained. Our study focuses on RNN-T and Conformer models, and we show that model quality does not drop even when the decoder is fully randomized. Furthermore, such models can be trained more efficiently as the decoders do not require to be updated. By contrast, randomizing encoders hurts model quality, indicating that optimizing encoders and learn proper representations for acoustic inputs are more vital for speech recognition. Overall, we challenge the common practice of training ASR models for all components, and demonstrate that ESN-based models can perform equally well but enable more efficient training and storage than fully-trainable counterparts.