 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-Time Error Analysis of Asynchronous Q-Learning with Discrete-Time Switching System Models
Paper and Code
Feb 22, 2021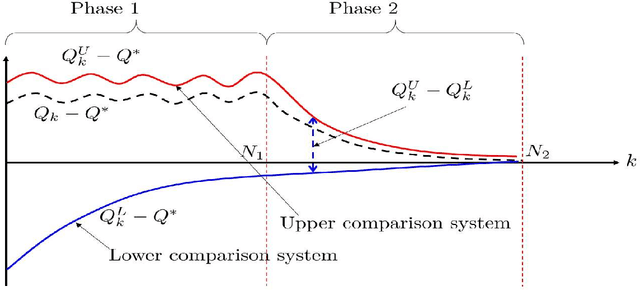
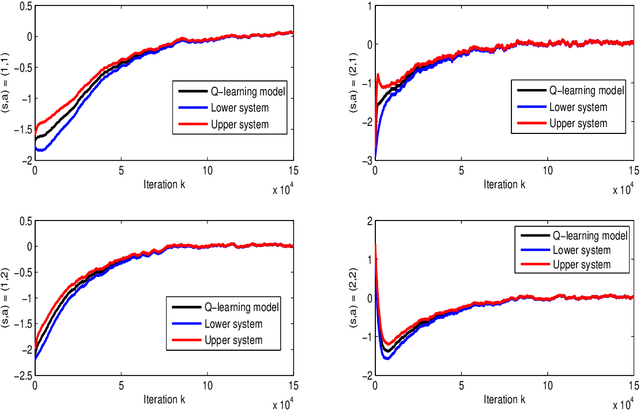
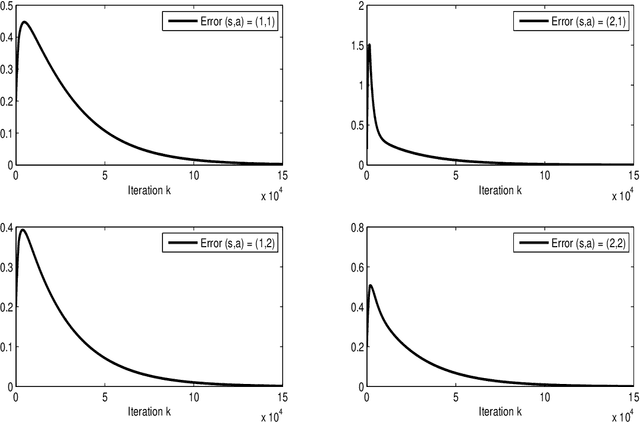
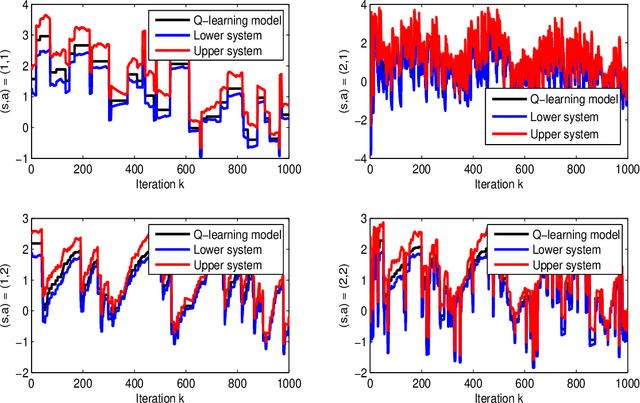
This paper develops a novel framework to analyze the convergence of Q-learning algorithm by using its connections to dynamical systems. We prove that asynchronous Q-learning with a constant step-size can be naturally formulated as discrete-time stochastic switched linear systems. Moreover, the evolution of the Q-learning estimation error is over- and underestimated by trajectories of two dynamical systems. Based on the schemes, a new finite-time analysis of the Q-learning is given with a finite-time error bound. It offers novel intuitive insights on analysis of Q-learning mainly based on control theoretic frameworks. By filling the gap between both domains in a synergistic way, this approach can potentially facilitate further progress in each field.