 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTableLab: An Interactive Table Extraction System with Adaptive Deep Learning
Paper and Code
Feb 16, 2021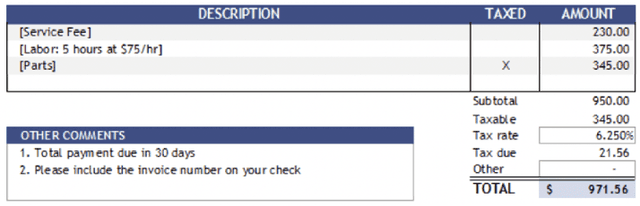
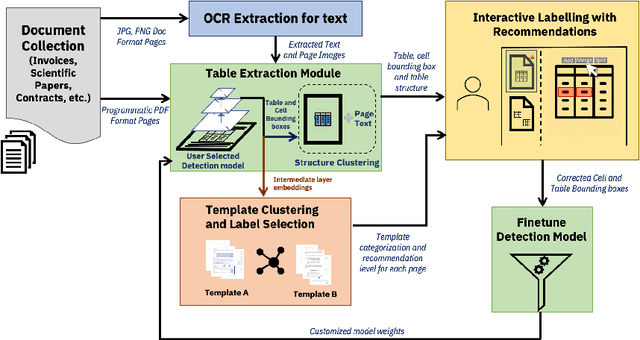

Table extraction from PDF and image documents is a ubiquitous task in the real-world. Perfect extraction quality is difficult to achieve with one single out-of-box model due to (1) the wide variety of table styles, (2) the lack of training data representing this variety and (3) the inherent ambiguity and subjectivity of table definitions between end-users. Meanwhile, building customized models from scratch can be difficult due to the expensive nature of annotating table data. We attempt to solve these challenges with TableLab by providing a system where users and models seamlessly work together to quickly customize high-quality extraction models with a few labelled examples for the user's document collection, which contains pages with tables. Given an input document collection, TableLab first detects tables with similar structures (templates) by clustering embeddings from the extraction model. Document collections often contain tables created with a limited set of templates or similar structures. It then selects a few representative table examples already extracted with a pre-trained base deep learning model. Via an easy-to-use user interface, users provide feedback to these selections without necessarily having to identify every single error. TableLab then applies such feedback to finetune the pre-trained model and returns the results of the finetuned model back to the user. The user can choose to repeat this process iteratively until obtaining a customized model with satisfactory performance.