 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Privacy-utility Trade-off Against a Hypothesis Testing Adversary
Paper and Code
Feb 18, 2021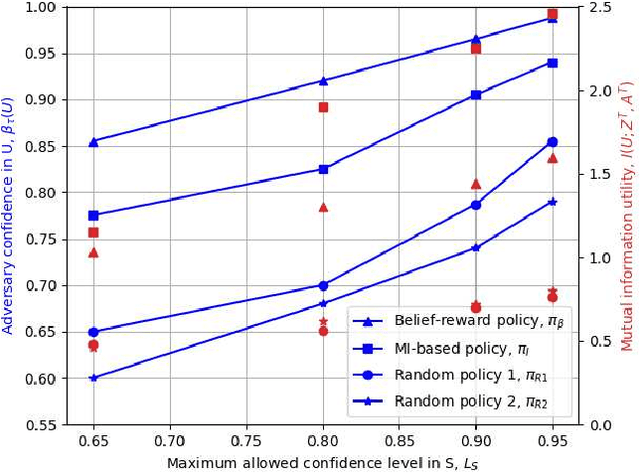
We consider a user releasing her data containing some personal information in return of a service. We model user's personal information as two correlated random variables, one of them, called the secret variable, is to be kept private, while the other, called the useful variable, is to be disclosed for utility. We consider active sequential data release, where at each time step the user chooses from among a finite set of release mechanisms, each revealing some information about the user's personal information, i.e., the true hypotheses, albeit with different statistics. The user manages data release in an online fashion such that maximum amount of information is revealed about the latent useful variable, while the confidence for the sensitive variable is kept below a predefined level. For the utility, we consider both the probability of correct detection of the useful variable and the mutual information (MI) between the useful variable and released data. We formulate both problems as a Markov decision process (MDP), and numerically solve them by advantage actor-critic (A2C) deep reinforcement learning (RL).