 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentanglement for audio-visual emotion recognition using multitask setup
Paper and Code
Feb 11, 2021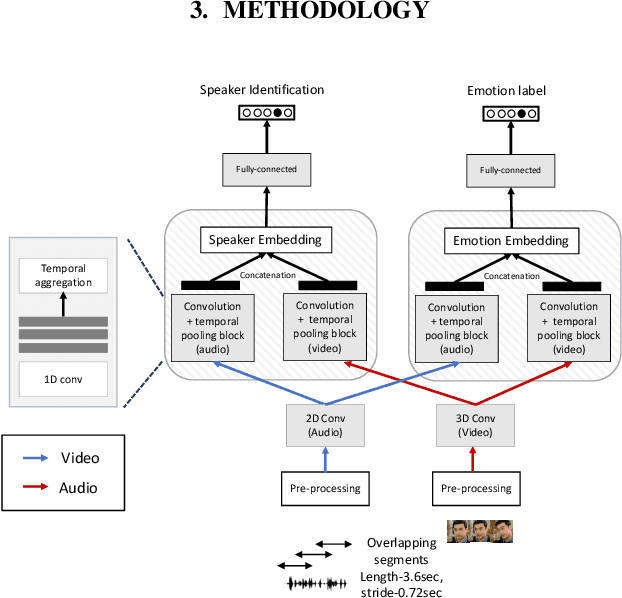
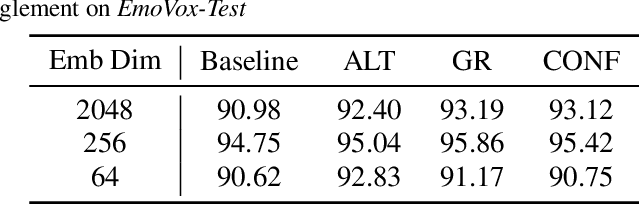
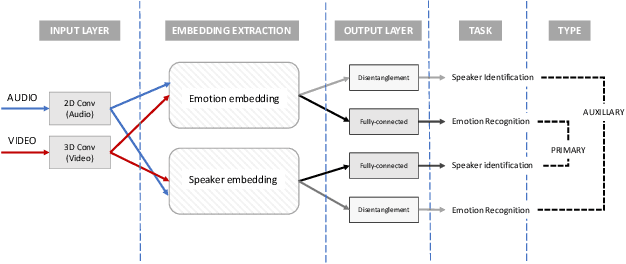
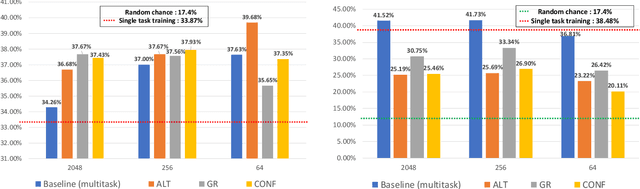
Deep learning models trained on audio-visual data have been successfully used to achieve state-of-the-art performance for emotion recognition. In particular, models trained with multitask learning have shown additional performance improvements. However, such multitask models entangle information between the tasks, encoding the mutual dependencies present in label distributions in the real world data used for training. This work explores the disentanglement of multimodal signal representations for the primary task of emotion recognition and a secondary person identification task. In particular, we developed a multitask framework to extract low-dimensional embeddings that aim to capture emotion specific information, while containing minimal information related to person identity. We evaluate three different techniques for disentanglement and report results of up to 13% disentanglement while maintaining emotion recognition performance.