 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation of End-to-End Models for Robust Speech Recognition
Paper and Code
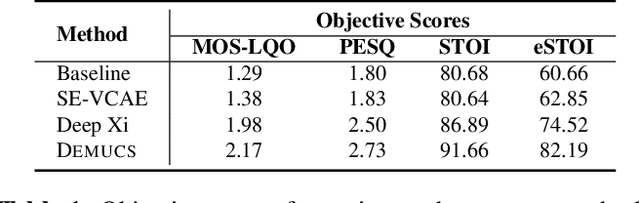
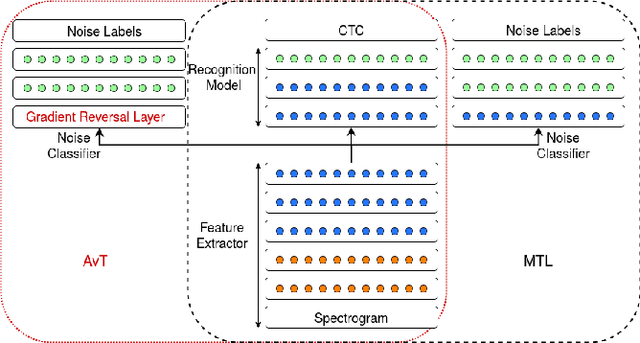
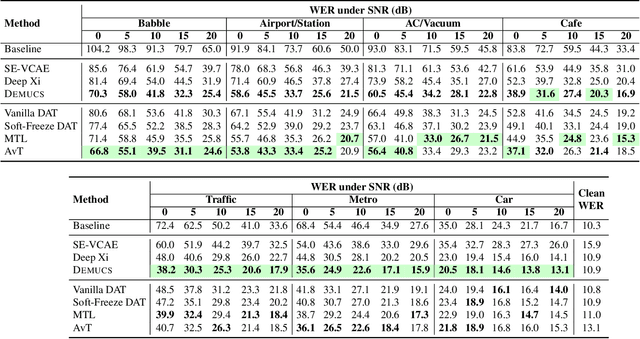
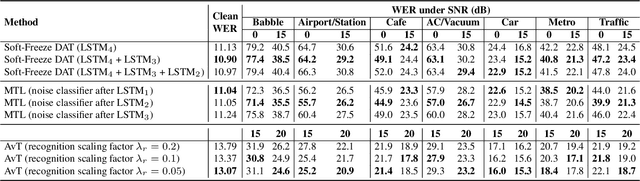
End-to-end models for robust automatic speech recognition (ASR) have not been sufficiently well-explored in prior work. With end-to-end models, one could choose to preprocess the input speech using speech enhancement techniques and train the model using enhanced speech. Another alternative is to pass the noisy speech as input and modify the model architecture to adapt to noisy speech. A systematic comparison of these two approaches for end-to-end robust ASR has not been attempted before. We address this gap and present a detailed comparison of speech enhancement-based techniques and three different model-based adaptation techniques covering data augmentation, multi-task learning, and adversarial learning for robust ASR. While adversarial learning is the best-performing technique on certain noise types, it comes at the cost of degrading clean speech WER. On other relatively stationary noise types, a new speech enhancement technique outperformed all the model-based adaptation techniques. This suggests that knowledge of the underlying noise type can meaningfully inform the choice of adaptation technique.