 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Can Models Learn From Explanations? A Formal Framework for Understanding the Roles of Explanation Data
Paper and Code

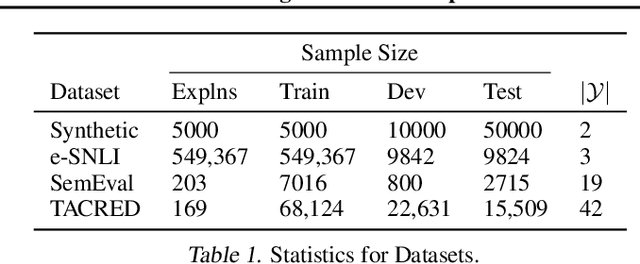
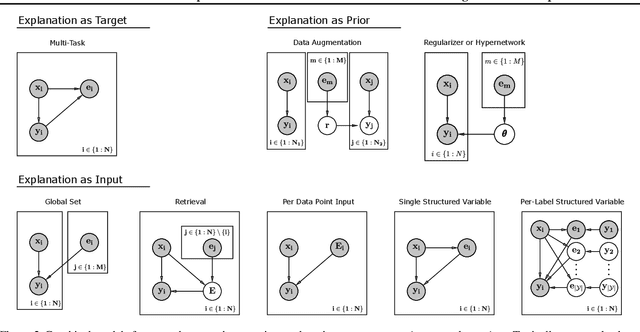

Many methods now exist for conditioning model outputs on task instructions, retrieved documents, and user-provided explanations and feedback. Rather than relying solely on examples of task inputs and outputs, these approaches use valuable additional data for improving model correctness and aligning learned models with human priors. Meanwhile, a growing body of evidence suggests that some language models can (1) store a large amount of knowledge in their parameters, and (2) perform inference over tasks in textual inputs at test time. These results raise the possibility that, for some tasks, humans cannot explain to a model any more about the task than it already knows or could infer on its own. In this paper, we study the circumstances under which explanations of individual data points can (or cannot) improve modeling performance. In order to carefully control important properties of the data and explanations, we introduce a synthetic dataset for experiments, and we also make use of three existing datasets with explanations: e-SNLI, TACRED, and SemEval. We first give a formal framework for the available modeling approaches, in which explanation data can be used as model inputs, as targets, or as a prior. After arguing that the most promising role for explanation data is as model inputs, we propose to use a retrieval-based method and show that it solves our synthetic task with accuracies upwards of 95%, while baselines without explanation data achieve below 65% accuracy. We then identify properties of datasets for which retrieval-based modeling fails. With the three existing datasets, we find no improvements from explanation retrieval. Drawing on findings from our synthetic task, we suggest that at least one of six preconditions for successful modeling fails to hold with these datasets. Our code is publicly available at https://github.com/peterbhase/ExplanationRoles