 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Large-Vocabulary Object Detectors: The Devil is in the Details
Paper and Code
Feb 01, 2021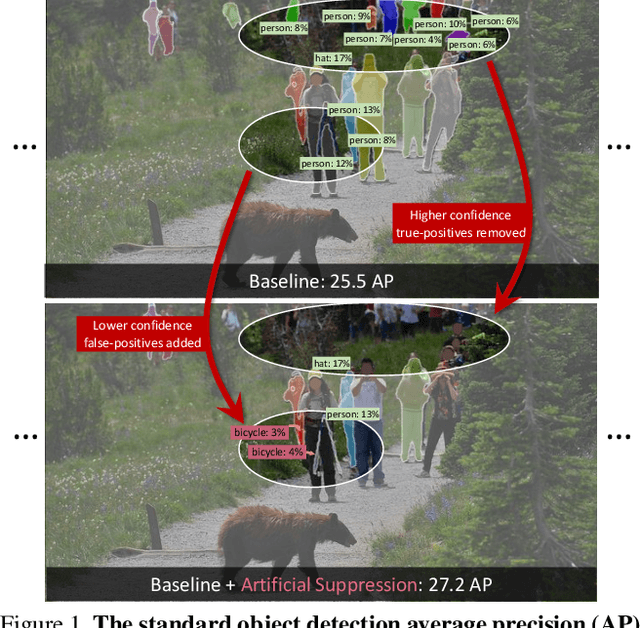

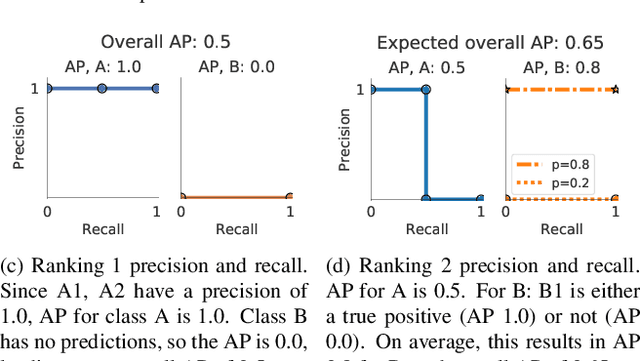
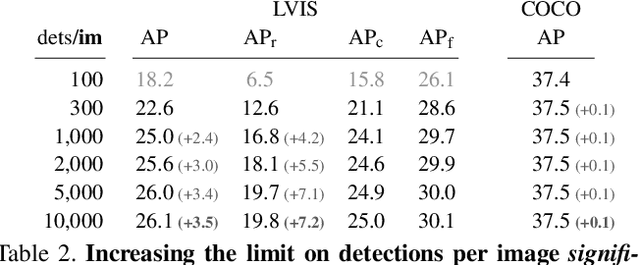
By design, average precision (AP) for object detection aims to treat all classes independently: AP is computed independently per category and averaged. On the one hand, this is desirable as it treats all classes, rare to frequent, equally. On the other hand, it ignores cross-category confidence calibration, a key property in real-world use cases. Unfortunately, we find that on imbalanced, large-vocabulary datasets, the default implementation of AP is neither category independent, nor does it directly reward properly calibrated detectors. In fact, we show that the default implementation produces a gameable metric, where a simple, nonsensical re-ranking policy can improve AP by a large margin. To address these limitations, we introduce two complementary metrics. First, we present a simple fix to the default AP implementation, ensuring that it is truly independent across categories as originally intended. We benchmark recent advances in large-vocabulary detection and find that many reported gains do not translate to improvements under our new per-class independent evaluation, suggesting recent improvements may arise from difficult to interpret changes to cross-category rankings. Given the importance of reliably benchmarking cross-category rankings, we consider a pooled version of AP (AP-pool) that rewards properly calibrated detectors by directly comparing cross-category rankings. Finally, we revisit classical approaches for calibration and find that explicitly calibrating detectors improves state-of-the-art on AP-pool by 1.7 points.