 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring spatial relations from textual descriptions of images
Paper and Code
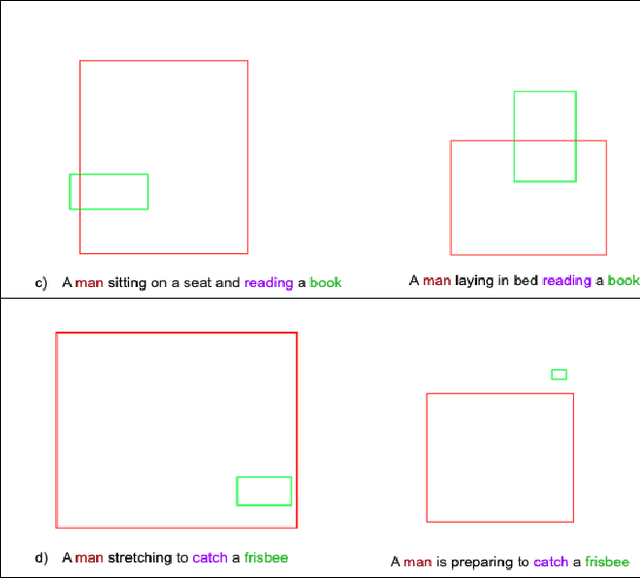



Generating an image from its textual description requires both a certain level of language understanding and common sense knowledge about the spatial relations of the physical entities being described. In this work, we focus on inferring the spatial relation between entities, a key step in the process of composing scenes based on text. More specifically, given a caption containing a mention to a subject and the location and size of the bounding box of that subject, our goal is to predict the location and size of an object mentioned in the caption. Previous work did not use the caption text information, but a manually provided relation holding between the subject and the object. In fact, the used evaluation datasets contain manually annotated ontological triplets but no captions, making the exercise unrealistic: a manual step was required; and systems did not leverage the richer information in captions. Here we present a system that uses the full caption, and Relations in Captions (REC-COCO), a dataset derived from MS-COCO which allows to evaluate spatial relation inference from captions directly. Our experiments show that: (1) it is possible to infer the size and location of an object with respect to a given subject directly from the caption; (2) the use of full text allows to place the object better than using a manually annotated relation. Our work paves the way for systems that, given a caption, decide which entities need to be depicted and their respective location and sizes, in order to then generate the final image.