 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Query Once: Effective Black Box Adversarial Attacks with Minimal Repeated Queries
Paper and Code
Jan 29, 2021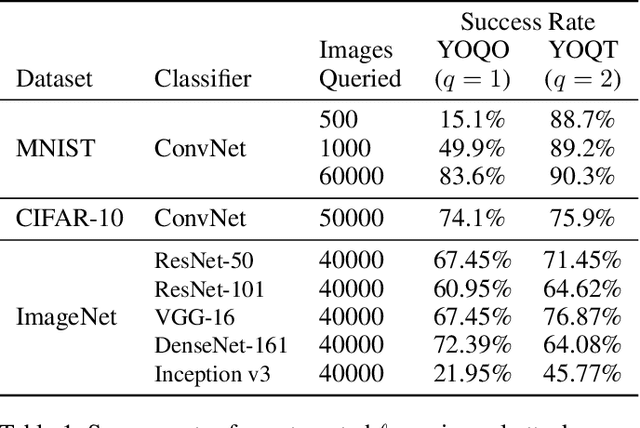



Researchers have repeatedly shown that it is possible to craft adversarial attacks on deep classifiers (small perturbations that significantly change the class label), even in the "black-box" setting where one only has query access to the classifier. However, all prior work in the black-box setting attacks the classifier by repeatedly querying the same image with minor modifications, usually thousands of times or more, making it easy for defenders to detect an ensuing attack. In this work, we instead show that it is possible to craft (universal) adversarial perturbations in the black-box setting by querying a sequence of different images only once. This attack prevents detection from high number of similar queries and produces a perturbation that causes misclassification when applied to any input to the classifier. In experiments, we show that attacks that adhere to this restriction can produce untargeted adversarial perturbations that fool the vast majority of MNIST and CIFAR-10 classifier inputs, as well as in excess of $60-70\%$ of inputs on ImageNet classifiers. In the targeted setting, we exhibit targeted black-box universal attacks on ImageNet classifiers with success rates above $20\%$ when only allowed one query per image, and $66\%$ when allowed two queries per image.