 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Robots to Draw and Tell: Towards Visually Grounded Multimodal Description Generation
Paper and Code
Jan 14, 2021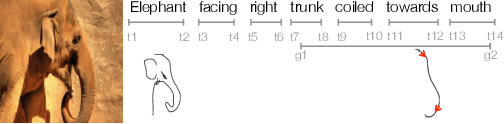
Socially competent robots should be equipped with the ability to perceive the world that surrounds them and communicate about it in a human-like manner. Representative skills that exhibit such ability include generating image descriptions and visually grounded referring expressions. In the NLG community, these generation tasks are largely investigated in non-interactive and language-only settings. However, in face-to-face interaction, humans often deploy multiple modalities to communicate, forming seamless integration of natural language, hand gestures and other modalities like sketches. To enable robots to describe what they perceive with speech and sketches/gestures, we propose to model the task of generating natural language together with free-hand sketches/hand gestures to describe visual scenes and real life objects, namely, visually-grounded multimodal description generation. In this paper, we discuss the challenges and evaluation metrics of the task, and how the task can benefit from progress recently made in the natural language processing and computer vision realms, where related topics such as visually grounded NLG, distributional semantics, and photo-based sketch generation have been extensively studied.