 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Based Temporal Logic Control with Soft Constraints Using Limit-deterministic Generalized Buchi Automata
Paper and Code
Jan 31, 2021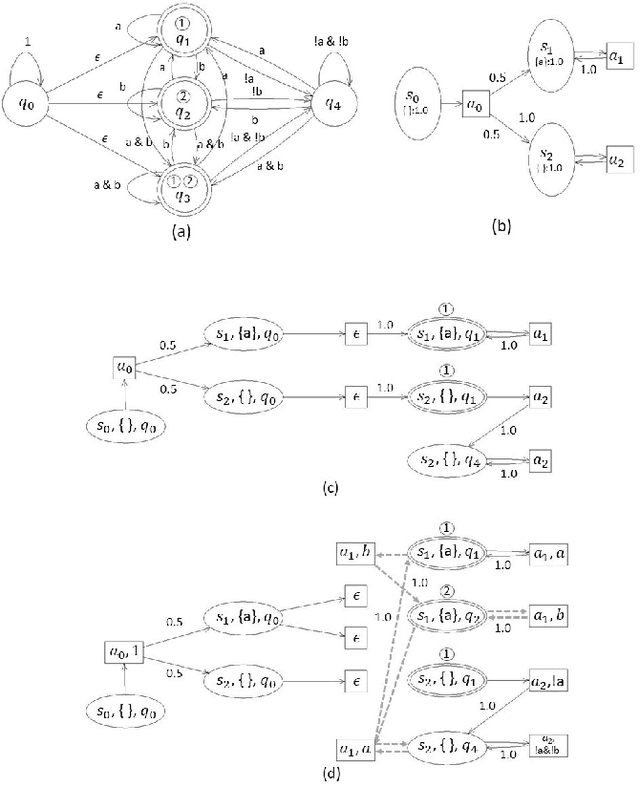
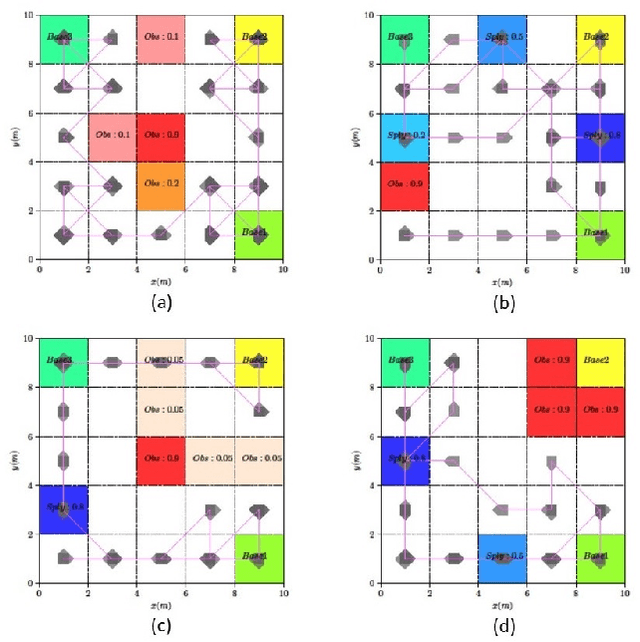
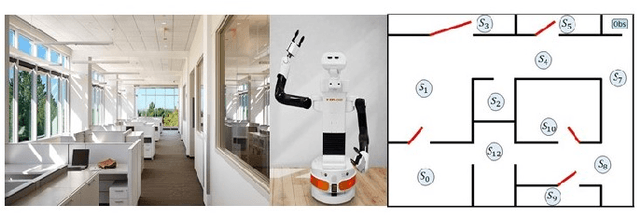
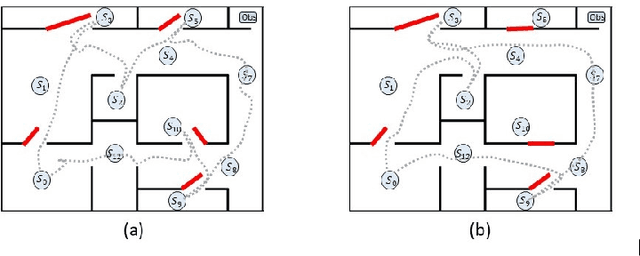
This paper studies the control synthesis of motion planning subject to uncertainties. The uncertainties are considered in robot motion and environment properties, giving rise to the probabilistic labeled Markov decision process (MDP). A model-free reinforcement learning (RL) is developed to generate a finite-memory control policy to satisfy high-level tasks expressed in linear temporal logic (LTL) formulas. One of the novelties is to translate LTL into a limit deterministic generalized B\"uchi automaton (LDGBA) and develop a corresponding embedded LDGBA (E-LDGBA) by incorporating a tracking-frontier function to overcome the issue of sparse accepting rewards, resulting in improved learning performance without increasing computational complexity. Due to potentially conflicting tasks, a relaxed product MDP is developed to allow the agent to revise its motion plan without strictly following the desired LTL constraints if the desired tasks can only be partially fulfilled. An expected return composed of violation rewards and accepting rewards is developed. The designed violation function quantifies the differences between the revised and the desired motion planning, while the accepting rewards are designed to enforce the satisfaction of the acceptance condition of the relaxed product MDP. Rigorous analysis shows that any RL algorithm that optimizes the expected return is guaranteed to find policies that, in decreasing order, can 1) satisfy acceptance condition of relaxed product MDP and 2) reduce the violation cost over long-term behaviors. Also, we validate the control synthesis approach via simulation and experimental results.