 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Interpretable Models into Human-Readable Code
Paper and Code
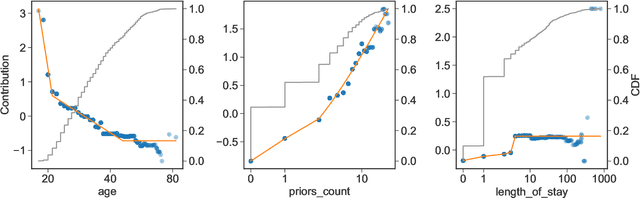
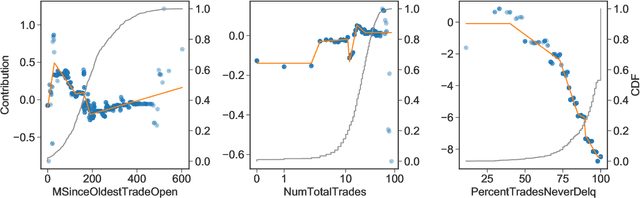
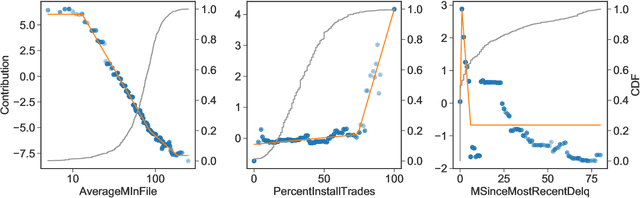
The goal of model distillation is to faithfully transfer teacher model knowledge to a model which is faster, more generalizable, more interpretable, or possesses other desirable characteristics. Human-readability is an important and desirable standard for machine-learned model interpretability. Readable models are transparent and can be reviewed, manipulated, and deployed like traditional source code. As a result, such models can be improved outside the context of machine learning and manually edited if desired. Given that directly training such models is difficult, we propose to train interpretable models using conventional methods, and then distill them into concise, human-readable code. The proposed distillation methodology approximates a model's univariate numerical functions with piecewise-linear curves in a localized manner. The resulting curve model representations are accurate, concise, human-readable, and well-regularized by construction. We describe a piecewise-linear curve-fitting algorithm that produces high-quality results efficiently and reliably across a broad range of use cases. We demonstrate the effectiveness of the overall distillation technique and our curve-fitting algorithm using four datasets across the tasks of classification, regression, and ranking.