 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Multimodal Sentiment Analysis in Car Reviews (MuSe-CaR) Dataset: Collection, Insights and Improvements
Paper and Code
Jan 15, 2021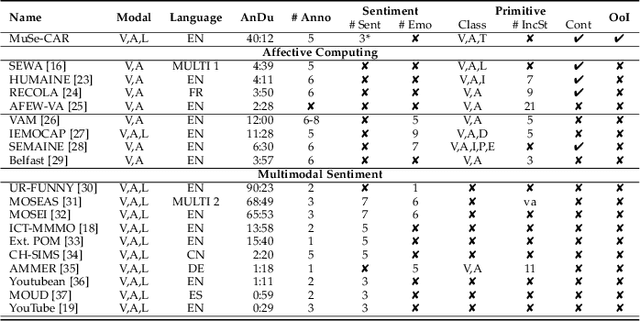

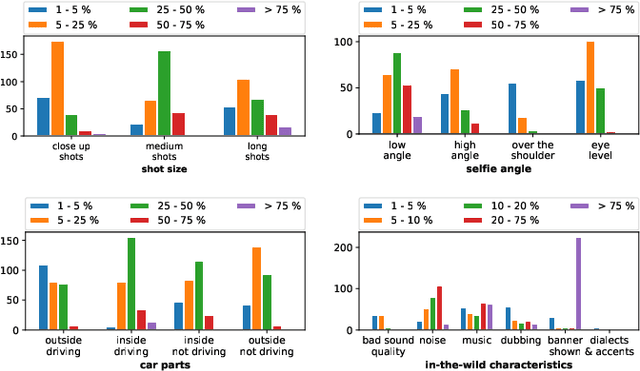
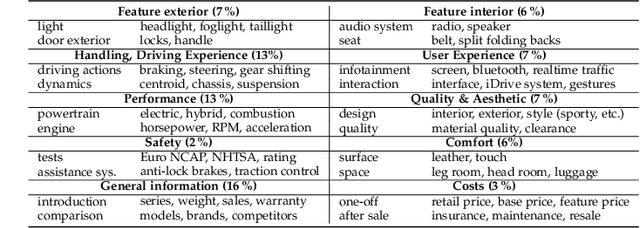
Truly real-life data presents a strong, but exciting challenge for sentiment and emotion research. The high variety of possible `in-the-wild' properties makes large datasets such as these indispensable with respect to building robust machine learning models. A sufficient quantity of data covering a deep variety in the challenges of each modality to force the exploratory analysis of the interplay of all modalities has not yet been made available in this context. In this contribution, we present MuSe-CaR, a first of its kind multimodal dataset. The data is publicly available as it recently served as the testing bed for the 1st Multimodal Sentiment Analysis Challenge, and focused on the tasks of emotion, emotion-target engagement, and trustworthiness recognition by means of comprehensively integrating the audio-visual and language modalities. Furthermore, we give a thorough overview of the dataset in terms of collection and annotation, including annotation tiers not used in this year's MuSe 2020. In addition, for one of the sub-challenges - predicting the level of trustworthiness - no participant outperformed the baseline model, and so we propose a simple, but highly efficient Multi-Head-Attention network that exceeds using multimodal fusion the baseline by around 0.2 CCC (almost 50 % improvement).