 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Training Pre-Trained Language Models for Zero- and Few-Shot Multi-Dialectal Arabic Sequence Labeling
Paper and Code
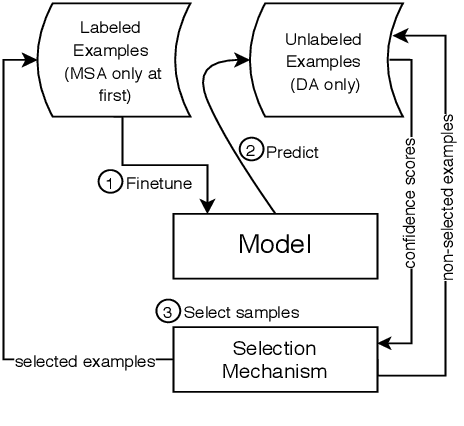
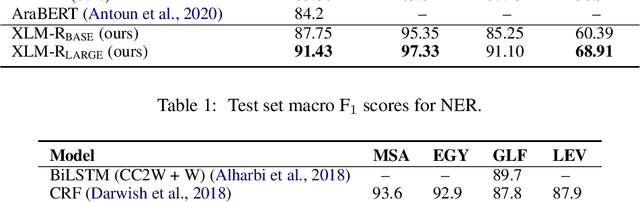

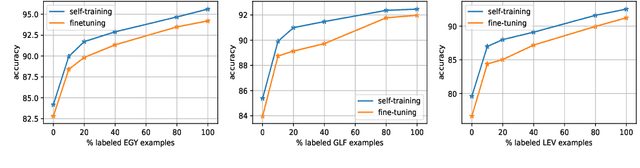
A sufficient amount of annotated data is usually required to fine-tune pre-trained language models for downstream tasks. Unfortunately, attaining labeled data can be costly, especially for multiple language varieties and dialects. We propose to self-train pre-trained language models in zero- and few-shot scenarios to improve performance on data-scarce varieties using only resources from data-rich ones. We demonstrate the utility of our approach in the context of Arabic sequence labeling by using a language model fine-tuned on Modern Standard Arabic (MSA) only to predict named entities (NE) and part-of-speech (POS) tags on several dialectal Arabic (DA) varieties. We show that self-training is indeed powerful, improving zero-shot MSA-to-DA transfer by as large as \texttildelow 10\% F$_1$ (NER) and 2\% accuracy (POS tagging). We acquire even better performance in few-shot scenarios with limited amounts of labeled data. We conduct an ablation study and show that the performance boost observed directly results from the unlabeled DA examples used for self-training. Our work opens up opportunities for developing DA models exploiting only MSA resources and it can be extended to other languages and tasks. Our code and fine-tuned models can be accessed at https://github.com/mohammadKhalifa/zero-shot-arabic-dialects.