 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Generalization of SGD-trained Neural Networks of Any Width in the Presence of Adversarial Label Noise
Paper and Code
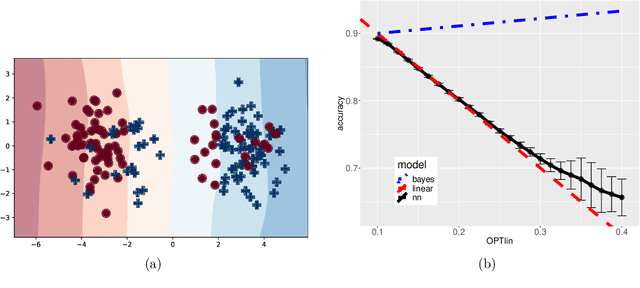

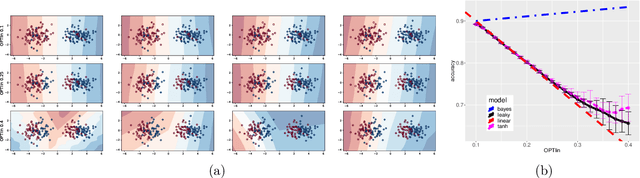
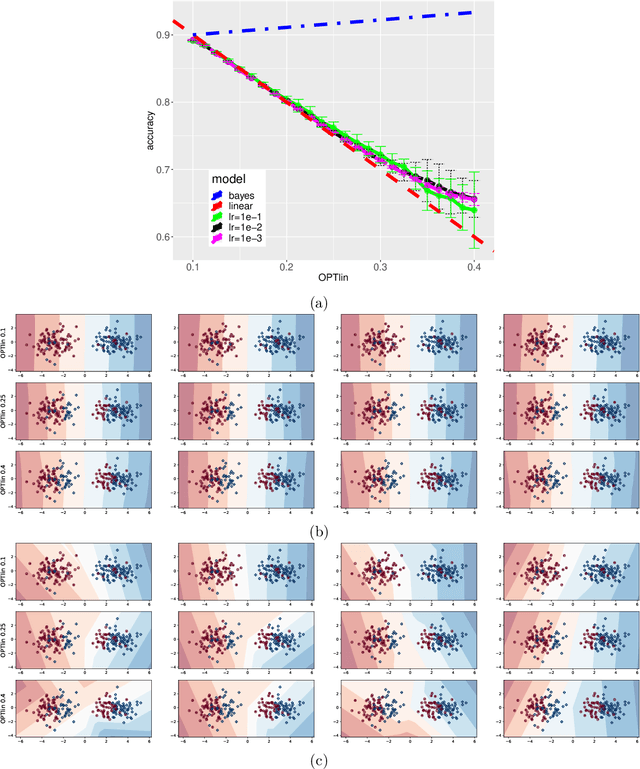
We consider a one-hidden-layer leaky ReLU network of arbitrary width trained by stochastic gradient descent following an arbitrary initialization. We prove that stochastic gradient descent (SGD) produces neural networks that have classification accuracy competitive with that of the best halfspace over the distribution for a broad class of distributions that includes log-concave isotropic and hard margin distributions. Equivalently, such networks can generalize when the data distribution is linearly separable but corrupted with adversarial label noise, despite the capacity to overfit. We conduct experiments which suggest that for some distributions our generalization bounds are nearly tight. This is the first result that shows that overparameterized neural networks trained by SGD can generalize when the data is corrupted with adversarial label noise.