 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from the Worst: Dynamically Generated Datasets to Improve Online Hate Detection
Paper and Code
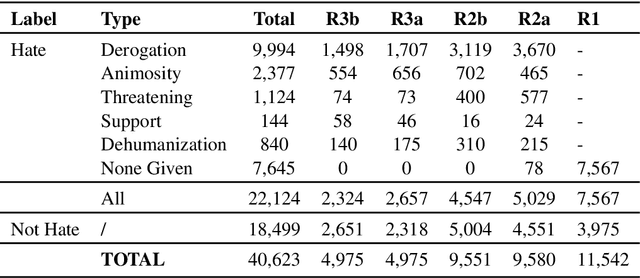
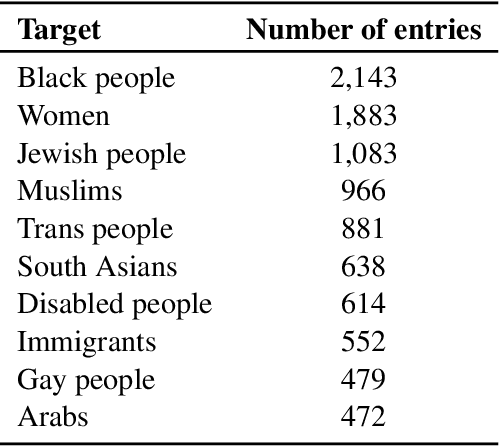
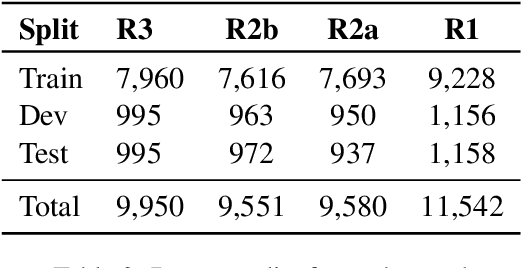
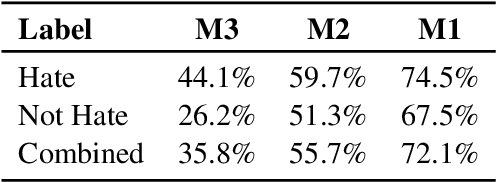
We present a first-of-its-kind large synthetic training dataset for online hate classification, created from scratch with trained annotators over multiple rounds of dynamic data collection. We provide a 40,623 example dataset with annotations for fine-grained labels, including a large number of challenging contrastive perturbation examples. Unusually for an abusive content dataset, it comprises 54% hateful and 46% not hateful entries. We show that model performance and robustness can be greatly improved using the dynamic data collection paradigm. The model error rate decreased across rounds, from 72.1% in the first round to 35.8% in the last round, showing that models became increasingly harder to trick -- even though content become progressively more adversarial as annotators became more experienced. Hate speech detection is an important and subtle problem that is still very challenging for existing AI methods. We hope that the models, dataset and dynamic system that we present here will help improve current approaches, having a positive social impact.