 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYASO: A New Benchmark for Targeted Sentiment Analysis
Paper and Code



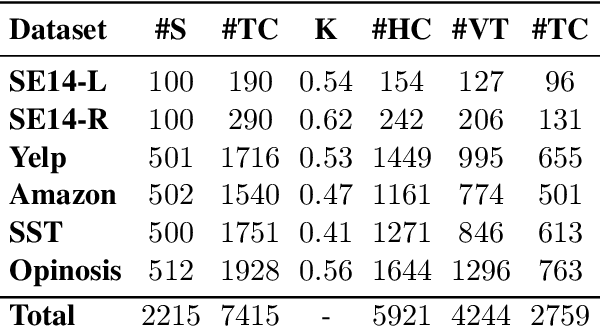
Sentiment analysis research has shifted over the years from the analysis of full documents or single sentences to a finer-level of detail -- identifying the sentiment towards single words or phrases -- with the task of Targeted Sentiment Analysis (TSA). While this problem is attracting a plethora of works focusing on algorithmic aspects, they are typically evaluated on a selection from a handful of datasets, and little effort, if any, is dedicated to the expansion of the available evaluation data. In this work, we present YASO -- a new crowd-sourced TSA evaluation dataset, collected using a new annotation scheme for labeling targets and their sentiments. The dataset contains 2,215 English sentences from movie, business and product reviews, and 7,415 terms and their corresponding sentiments annotated within these sentences. Our analysis verifies the reliability of our annotations, and explores the characteristics of the collected data. Lastly, benchmark results using five contemporary TSA systems lay the foundation for future work, and show there is ample room for improvement on this challenging new dataset.