 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining NLP Models via Minimal Contrastive Editing (MiCE)
Paper and Code
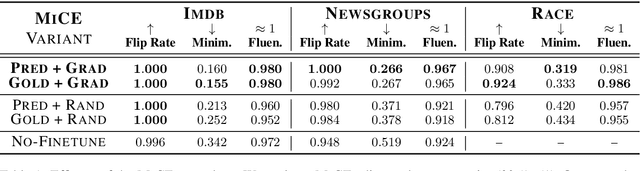
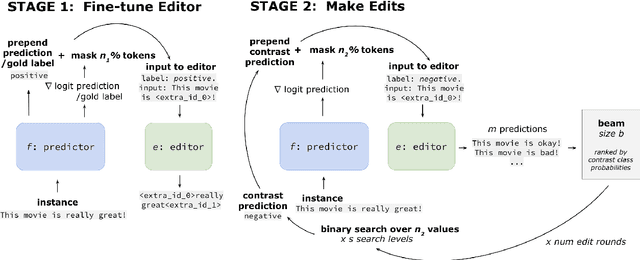
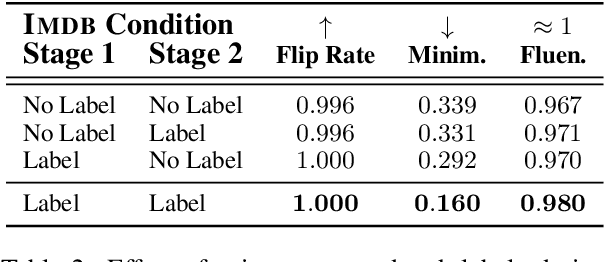
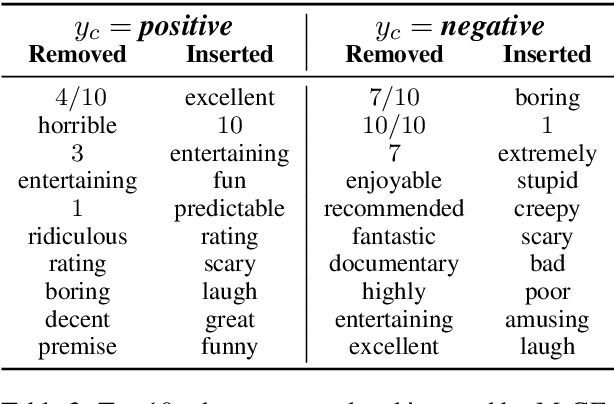
Humans give contrastive explanations that explain why an observed event happened rather than some other counterfactual event (the contrast case). Despite the important role that contrastivity plays in how people generate and evaluate explanations, this property is largely missing from current methods for explaining NLP models. We present Minimal Contrastive Editing (MiCE), a method for generating contrastive explanations of model predictions in the form of edits to inputs that change model outputs to the contrast case. Our experiments across three tasks -- binary sentiment classification, topic classification, and multiple-choice question answering -- show that MiCE is able to produce edits that are not only contrastive, but also minimal and fluent, consistent with human contrastive edits. We demonstrate how MiCE edits can be used for two use cases in NLP system development -- uncovering dataset artifacts and debugging incorrect model predictions -- and thereby illustrate that generating contrastive explanations is a promising research direction for model interpretability.