Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeDAL: Medical Abbreviation Disambiguation Dataset for Natural Language Understanding Pretraining
Paper and Code
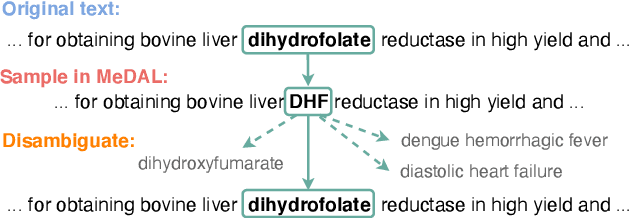

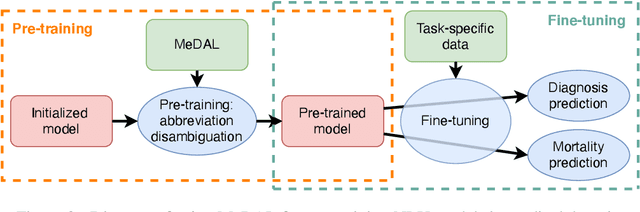
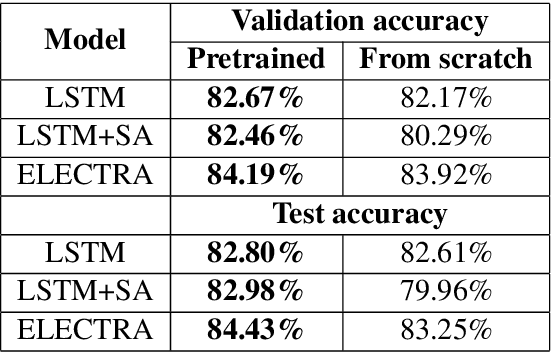
One of the biggest challenges that prohibit the use of many current NLP methods in clinical settings is the availability of public datasets. In this work, we present MeDAL, a large medical text dataset curated for abbreviation disambiguation, designed for natural language understanding pre-training in the medical domain. We pre-trained several models of common architectures on this dataset and empirically showed that such pre-training leads to improved performance and convergence speed when fine-tuning on downstream medical tasks.
* In Proceedings of the 3rd Clinical Natural Language Processing
Workshop, pp. 130-135. 2020 * EMNLP 2020 Clinical NLP
View paper on