 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Predicting the Characteristics of Test Collections
Paper and Code

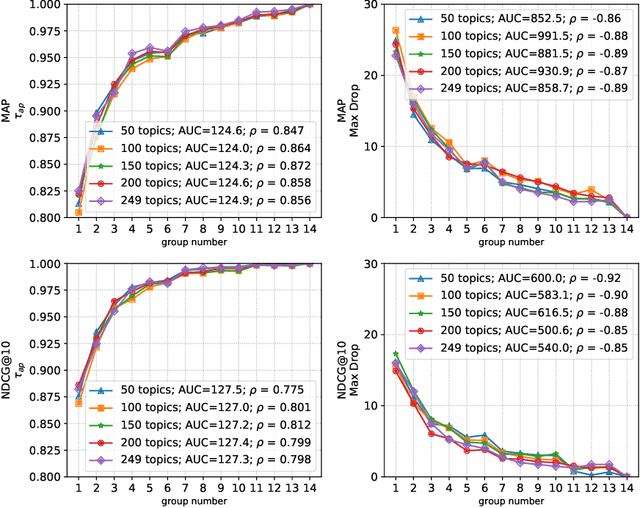
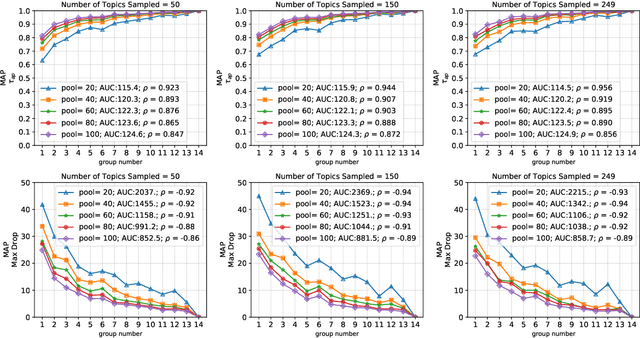
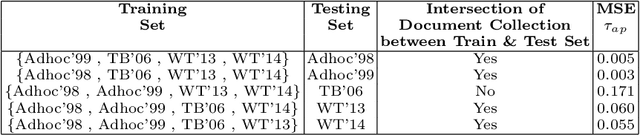
Shared-task campaigns such as NIST TREC select documents to judge by pooling rankings from many participant systems. Therefore, the quality of the test collection greatly depends on the number of participants and the quality of submitted runs. In this work, we investigate i) how the number of participants, coupled with other factors, affects the quality of a test collection; and ii) whether the quality of a test collection can be inferred prior to collecting relevance judgments. Experiments on six TREC collections demonstrate that the required number of participants to construct a high-quality test collection varies significantly across different test collections due to a variety of factors. Furthermore, results suggest that the quality of test collections can be predicted.