 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Using Classification Datasets to Evaluate Graph Outlier Detection: Peculiar Observations and New Insights
Paper and Code
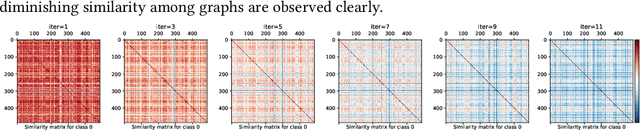
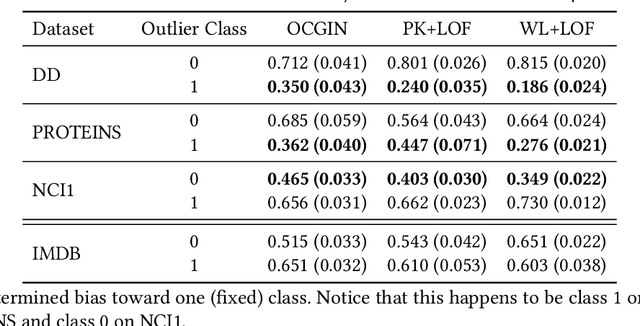
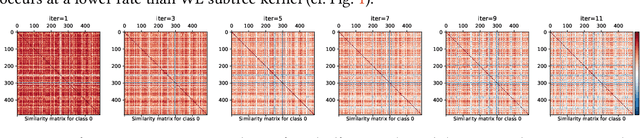
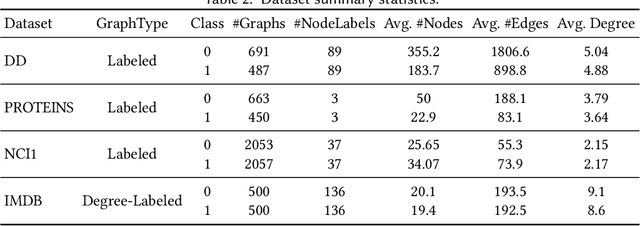
It is common practice of the outlier mining community to repurpose classification datasets toward evaluating various detection models. To that end, often a binary classification dataset is used, where samples from (typically, the larger) one of the classes is designated as the inlier samples, and the other class is substantially down-sampled to create the (ground-truth) outlier samples. In this study, we identify an intriguing issue with repurposing graph classification datasets for graph outlier detection in this manner. Surprisingly, the detection performance of outlier models depends significantly on which class is down-sampled; put differently, accuracy often flips from high to low depending on which of the classes is down-sampled to represent the outlier samples. The problem is notably exacerbated particularly for a certain family of propagation based outlier detection models. Through careful analysis, we show that this issue mainly stems from disparate within-class sample similarity - which is amplified by various propagation based models - that impacts key characteristics of inlier/outlier distributions and indirectly, the difficulty of the outlier detection task and hence performance outcomes. With this study, we aim to draw attention to this (to our knowledge) previously-unnoticed issue, as it has implications for fair and effective evaluation of detection models, and hope that it will motivate the design of better evaluation benchmarks for outlier detection. Finally, we discuss the possibly overarching implications of using propagation based models on datasets with disparate within-class sample similarity beyond outlier detection, specifically for graph classification and graph-level clustering tasks.