 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Lay Language Summarization of Biomedical Scientific Reviews
Paper and Code
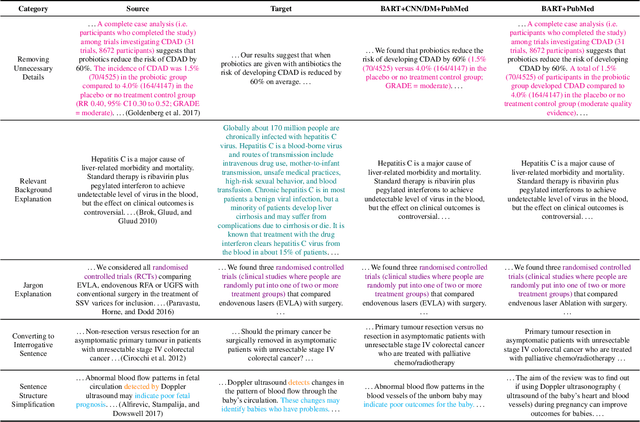
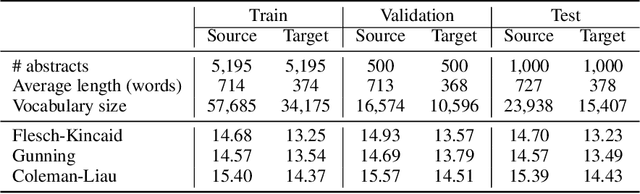
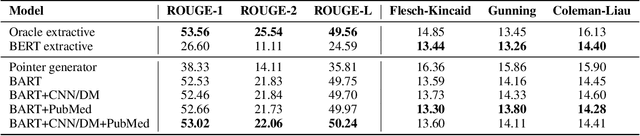
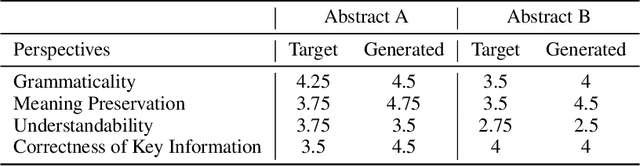
Health literacy has emerged as a crucial factor in making appropriate health decisions and ensuring treatment outcomes. However, medical jargon and the complex structure of professional language in this domain make health information especially hard to interpret. Thus, there is an urgent unmet need for automated methods to enhance the accessibility of the biomedical literature to the general population. This problem can be framed as a type of translation problem between the language of healthcare professionals, and that of the general public. In this paper, we introduce the novel task of automated generation of lay language summaries of biomedical scientific reviews, and construct a dataset to support the development and evaluation of automated methods through which to enhance the accessibility of the biomedical literature. We conduct analyses of the various challenges in solving this task, including not only summarization of the key points but also explanation of background knowledge and simplification of professional language. We experiment with state-of-the-art summarization models as well as several data augmentation techniques, and evaluate their performance using both automated metrics and human assessment. Results indicate that automatically generated summaries produced using contemporary neural architectures can achieve promising quality and readability as compared with reference summaries developed for the lay public by experts (best ROUGE-L of 50.24 and Flesch-Kincaid readability score of 13.30). We also discuss the limitations of the current attempt, providing insights and directions for future work.