 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Speaker Diarization as Post-Processing
Paper and Code
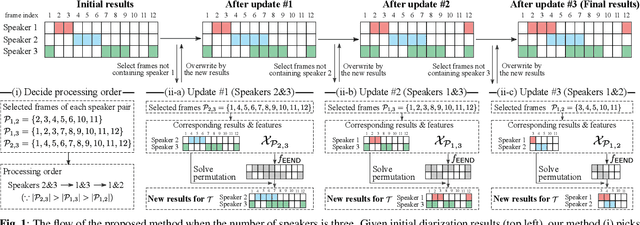
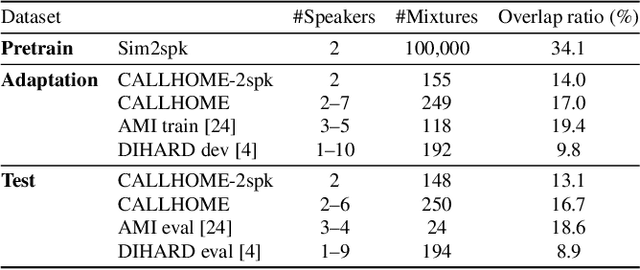
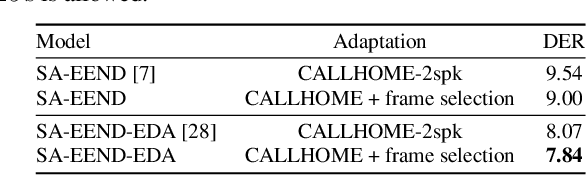
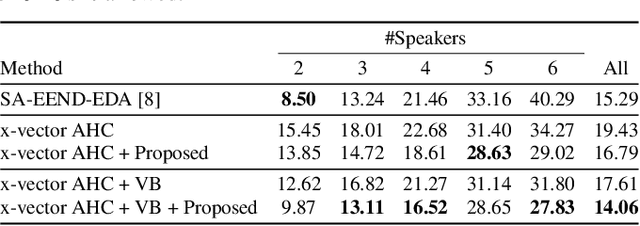
This paper investigates the utilization of an end-to-end diarization model as post-processing of conventional clustering-based diarization. Clustering-based diarization methods partition frames into clusters of the number of speakers; thus, they typically cannot handle overlapping speech because each frame is assigned to one speaker. On the other hand, some end-to-end diarization methods can handle overlapping speech by treating the problem as multi-label classification. Although some methods can treat a flexible number of speakers, they do not perform well when the number of speakers is large. To compensate for each other's weakness, we propose to use a two-speaker end-to-end diarization method as post-processing of the results obtained by a clustering-based method. We iteratively select two speakers from the results and update the results of the two speakers to improve the overlapped region. Experimental results show that the proposed algorithm consistently improved the performance of the state-of-the-art methods across CALLHOME, AMI, and DIHARD II datasets.