 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign-gram : Rethinking the Skip-gram Model for Protein Sequence Analysis
Paper and Code
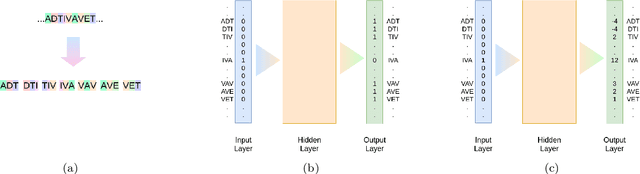

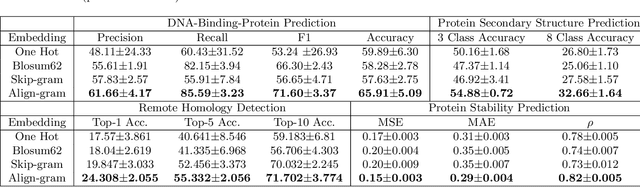
Background: The inception of next generations sequencing technologies have exponentially increased the volume of biological sequence data. Protein sequences, being quoted as the `language of life', has been analyzed for a multitude of applications and inferences. Motivation: Owing to the rapid development of deep learning, in recent years there have been a number of breakthroughs in the domain of Natural Language Processing. Since these methods are capable of performing different tasks when trained with a sufficient amount of data, off-the-shelf models are used to perform various biological applications. In this study, we investigated the applicability of the popular Skip-gram model for protein sequence analysis and made an attempt to incorporate some biological insights into it. Results: We propose a novel $k$-mer embedding scheme, Align-gram, which is capable of mapping the similar $k$-mers close to each other in a vector space. Furthermore, we experiment with other sequence-based protein representations and observe that the embeddings derived from Align-gram aids modeling and training deep learning models better. Our experiments with a simple baseline LSTM model and a much complex CNN model of DeepGoPlus shows the potential of Align-gram in performing different types of deep learning applications for protein sequence analysis.