 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Semi-Supervised Action Recognition with Active Learning
Paper and Code
Dec 07, 2020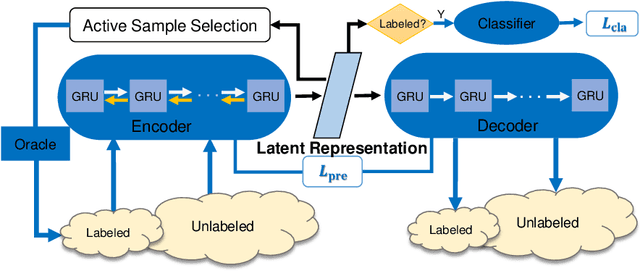
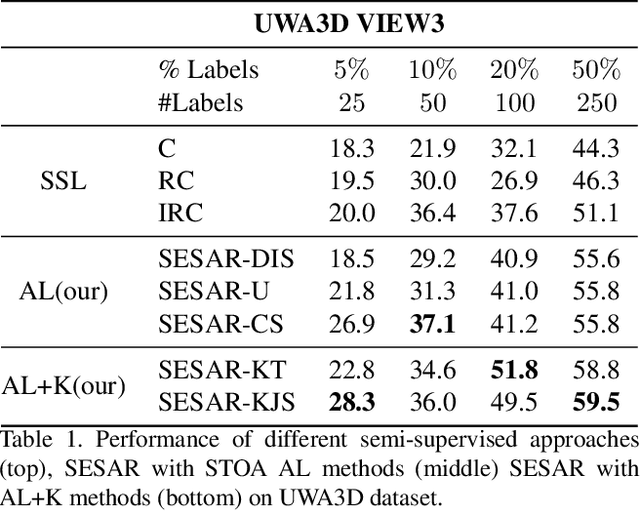
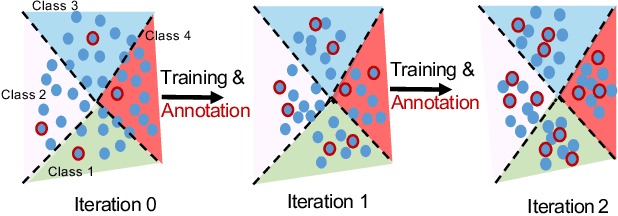
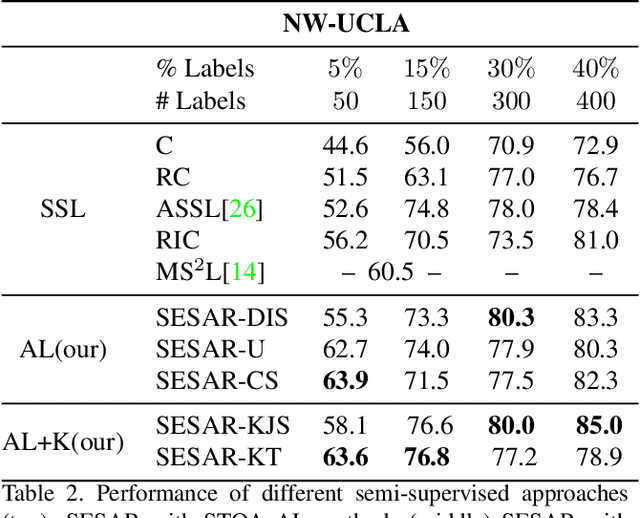
Current state-of-the-art methods for skeleton-based action recognition are supervised and rely on labels. The reliance is limiting the performance due to the challenges involved in annotation and mislabeled data. Unsupervised methods have been introduced, however, they organize sequences into clusters and still require labels to associate clusters with actions. In this paper, we propose a novel approach for skeleton-based action recognition, called SESAR, that connects these approaches. SESAR leverages the information from both unlabeled data and a handful of sequences actively selected for labeling, combining unsupervised training with sparsely supervised guidance. SESAR is composed of two main components, where the first component learns a latent representation for unlabeled action sequences through an Encoder-Decoder RNN which reconstructs the sequences, and the second component performs active learning to select sequences to be labeled based on cluster and classification uncertainty. When the two components are simultaneously trained on skeleton-based action sequences, they correspond to a robust system for action recognition with only a handful of labeled samples. We evaluate our system on common datasets with multiple sequences and actions, such as NW UCLA, NTU RGB+D 60, and UWA3D. Our results outperform standalone skeleton-based supervised, unsupervised with cluster identification, and active-learning methods for action recognition when applied to sparse labeled samples, as low as 1% of the data.