 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCircles are like Ellipses, or Ellipses are like Circles? Measuring the Degree of Asymmetry of Static and Contextual Embeddings and the Implications to Representation Learning
Paper and Code
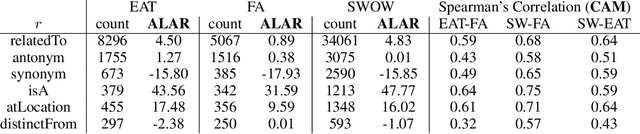
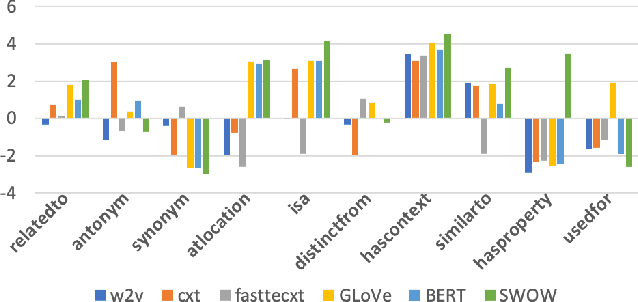
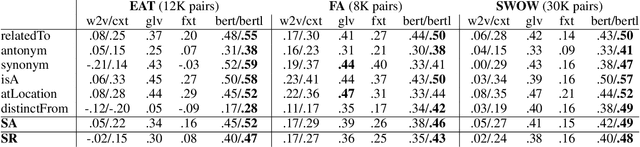
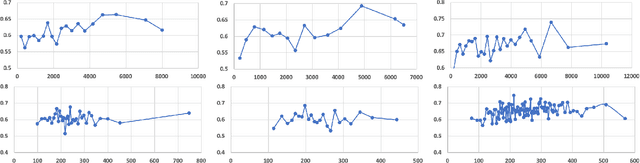
Human judgments of word similarity have been a popular method of evaluating the quality of word embedding. But it fails to measure the geometry properties such as asymmetry. For example, it is more natural to say "Ellipses are like Circles" than "Circles are like Ellipses". Such asymmetry has been observed from a psychoanalysis test called word evocation experiment, where one word is used to recall another. Although useful, such experimental data have been significantly understudied for measuring embedding quality. In this paper, we use three well-known evocation datasets to gain insights into asymmetry encoding of embedding. We study both static embedding as well as contextual embedding, such as BERT. Evaluating asymmetry for BERT is generally hard due to the dynamic nature of embedding. Thus, we probe BERT's conditional probabilities (as a language model) using a large number of Wikipedia contexts to derive a theoretically justifiable Bayesian asymmetry score. The result shows that contextual embedding shows randomness than static embedding on similarity judgments while performing well on asymmetry judgment, which aligns with its strong performance on "extrinsic evaluations" such as text classification. The asymmetry judgment and the Bayesian approach provides a new perspective to evaluate contextual embedding on intrinsic evaluation, and its comparison to similarity evaluation concludes our work with a discussion on the current state and the future of representation learning.