 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence and Sample Complexity of SGD in GANs
Paper and Code
Dec 01, 2020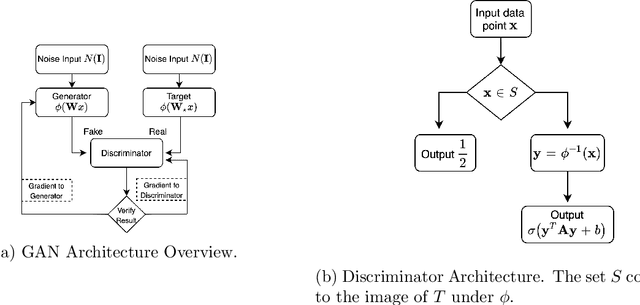
We provide theoretical convergence guarantees on training Generative Adversarial Networks (GANs) via SGD. We consider learning a target distribution modeled by a 1-layer Generator network with a non-linear activation function $\phi(\cdot)$ parametrized by a $d \times d$ weight matrix $\mathbf W_*$, i.e., $f_*(\mathbf x) = \phi(\mathbf W_* \mathbf x)$. Our main result is that by training the Generator together with a Discriminator according to the Stochastic Gradient Descent-Ascent iteration proposed by Goodfellow et al. yields a Generator distribution that approaches the target distribution of $f_*$. Specifically, we can learn the target distribution within total-variation distance $\epsilon$ using $\tilde O(d^2/\epsilon^2)$ samples which is (near-)information theoretically optimal. Our results apply to a broad class of non-linear activation functions $\phi$, including ReLUs and is enabled by a connection with truncated statistics and an appropriate design of the Discriminator network. Our approach relies on a bilevel optimization framework to show that vanilla SGDA works.