 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralAnnot: Neural Annotator for in-the-wild Expressive 3D Human Pose and Mesh Training Sets
Paper and Code
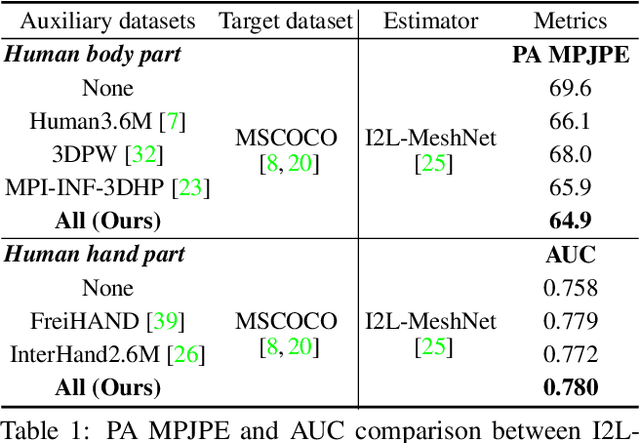
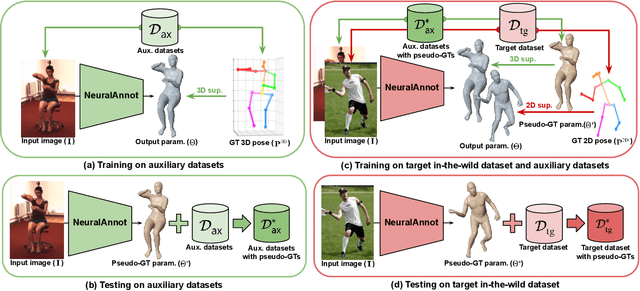

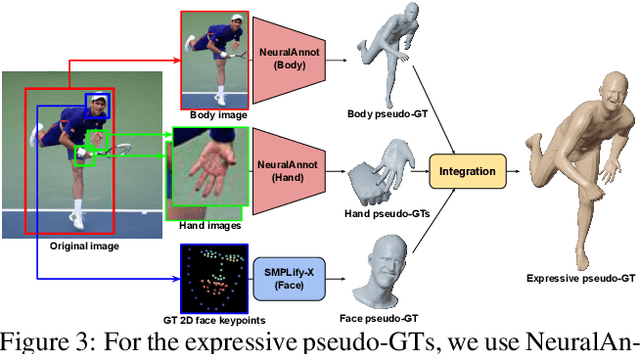
Recovering expressive 3D human pose and mesh from in-the-wild images is greatly challenging due to the absence of the training data. Several optimization-based methods have been used to obtain pseudo-groundtruth (GT) 3D poses and meshes from GT 2D poses. However, they often produce bad ones with long running time because their frameworks are optimized on each sample only using 2D supervisions in a sequential way. To overcome the limitations, we present NeuralAnnot, a neural annotator that learns to construct in-the-wild expressive 3D human pose and mesh training sets. Our NeuralAnnot is trained on a large number of samples by 2D supervisions from a target in-the-wild dataset and 3D supervisions from auxiliary datasets with GT 3D poses in a parallel way. We show that our NeuralAnnot produces far better 3D pseudo-GTs with much shorter running time than the optimization-based methods, and the newly obtained training set brings great performance gain. The newly obtained training sets and codes will be publicly available.