 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Two-Phase Approach for Abstractive Podcast Summarization
Paper and Code
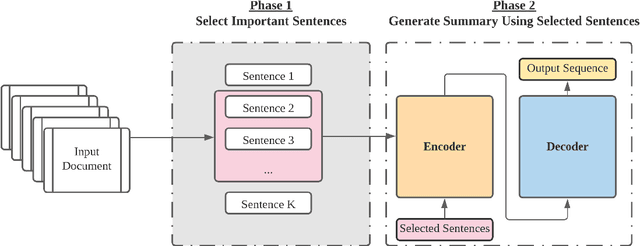


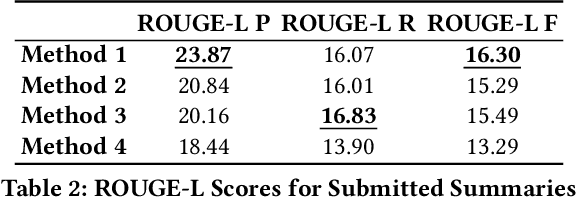
Podcast summarization is different from summarization of other data formats, such as news, patents, and scientific papers in that podcasts are often longer, conversational, colloquial, and full of sponsorship and advertising information, which imposes great challenges for existing models. In this paper, we focus on abstractive podcast summarization and propose a two-phase approach: sentence selection and seq2seq learning. Specifically, we first select important sentences from the noisy long podcast transcripts. The selection is based on sentence similarity to the reference to reduce the redundancy and the associated latent topics to preserve semantics. Then the selected sentences are fed into a pre-trained encoder-decoder framework for the summary generation. Our approach achieves promising results regarding both ROUGE-based measures and human evaluations.