 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end spoken language understanding using transformer networks and self-supervised pre-trained features
Paper and Code
Nov 16, 2020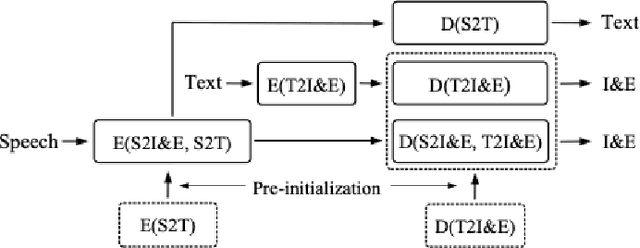
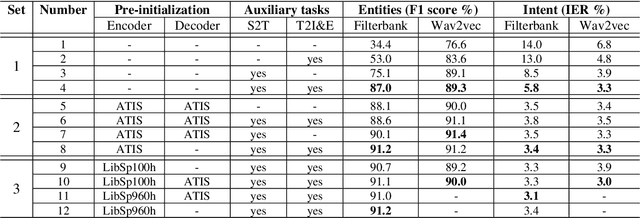


Transformer networks and self-supervised pre-training have consistently delivered state-of-art results in the field of natural language processing (NLP); however, their merits in the field of spoken language understanding (SLU) still need further investigation. In this paper we introduce a modular End-to-End (E2E) SLU transformer network based architecture which allows the use of self-supervised pre-trained acoustic features, pre-trained model initialization and multi-task training. Several SLU experiments for predicting intent and entity labels/values using the ATIS dataset are performed. These experiments investigate the interaction of pre-trained model initialization and multi-task training with either traditional filterbank or self-supervised pre-trained acoustic features. Results show not only that self-supervised pre-trained acoustic features outperform filterbank features in almost all the experiments, but also that when these features are used in combination with multi-task training, they almost eliminate the necessity of pre-trained model initialization.