 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTweet Sentiment Quantification: An Experimental Re-Evaluation
Paper and Code
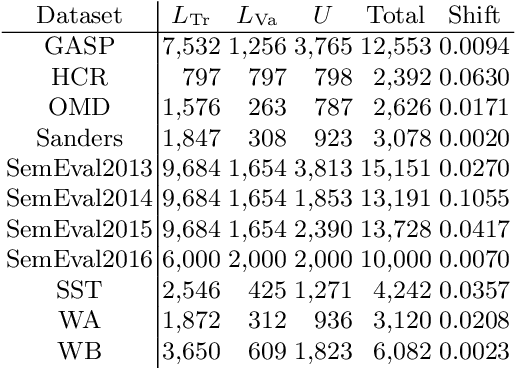
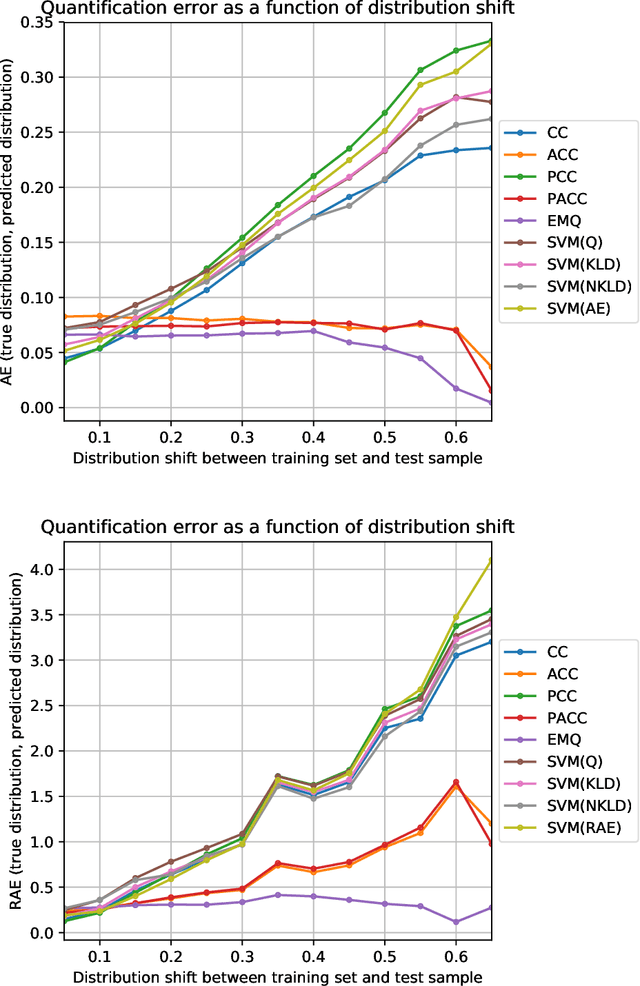
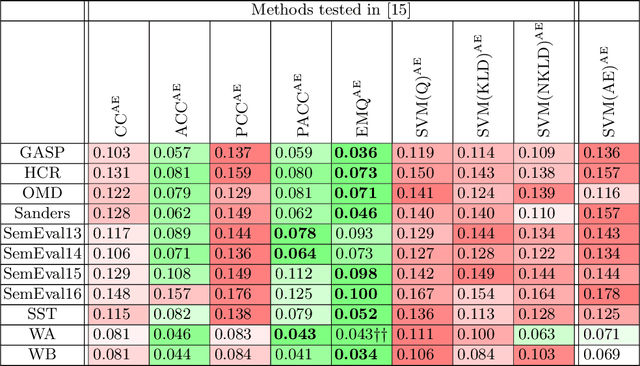
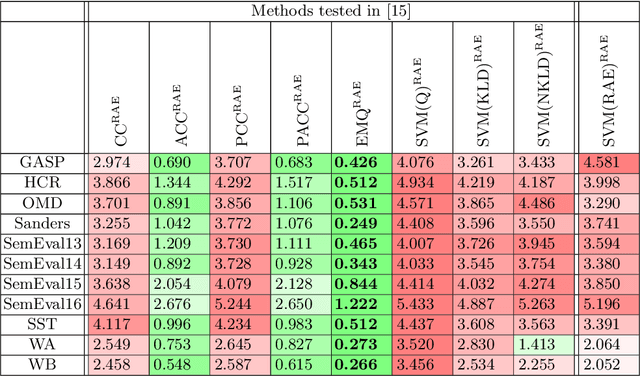
Sentiment quantification is the task of estimating the relative frequency (or "prevalence") of sentiment-related classes (such as Positive, Neutral, Negative) in a sample of unlabelled texts; this is especially important when these texts are tweets, since most sentiment classification endeavours carried out on Twitter data actually have quantification (and not the classification of individual tweets) as their ultimate goal. It is well-known that solving quantification via "classify and count" (i.e., by classifying all unlabelled items via a standard classifier and counting the items that have been assigned to a given class) is suboptimal in terms of accuracy, and that more accurate quantification methods exist. In 2016, Gao and Sebastiani carried out a systematic comparison of quantification methods on the task of tweet sentiment quantification. In hindsight, we observe that the experimental protocol followed in that work is flawed, and that its results are thus unreliable. We now re-evaluate those quantification methods on the very same datasets, this time following a now consolidated and much more robust experimental protocol, that involves 5775 as many experiments as run in the original study. Our experimentation yields results dramatically different from those obtained by Gao and Sebastiani, and thus provide a different, much more solid understanding of the relative strengths and weaknesses of different sentiment quantification methods.